통찰력 있는 IT 기업 비젠소프트를 소개합니다.
-
통찰력 있는 사람들이 함께하는 젊고 열정적인 IT 기업, 비젠소프트.
A young and passionate technology company,
brought together by people with keen insight—this is Vizensoft. -

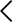 Back
BackSLM 소형 언어모델, GPT-4보다 100배 저렴한 AI 구축 가능할까?
SLM 소형 언어모델, GPT-4보다 100배 저렴한 AI 구축 가능할까? - "GPT-4로 챗봇 만들어봤더니 한 달 API 비용이 수백만 원이 나왔어요. 도저히 사업화가 안 되겠

# SLM 소형 언어모델, GPT-4보다 100배 저렴한 AI 구축 가능할까? 🤖💡
경량 LLM의 기술적 진화와 온디바이스 AI 시대, 당신의 비즈니스는 준비되어 있습니까?
---
---
도입부: "AI 도입하고 싶은데, 비용이 너무 무섭다"는 분들께
"GPT-4로 챗봇 만들어봤더니 한 달 API 비용이 수백만 원이 나왔어요. 도저히 사업화가 안 되겠더라고요."
이런 하소연, 한 번쯤 들어보셨거나 직접 겪어보신 분들이 많을 겁니다. 실제로 GPT-4 Turbo 기준 입력 토큰 1백만 개당 약 10달러, 출력은 30달러 수준입니다. 하루 1만 건의 고객 문의를 처리하는 중소기업 챗봇이라면 한 달 API 비용만 수천만 원에 달하는 경우도 생깁니다. AI 기술은 분명히 필요한데, 대형 모델의 비용 장벽이 너무 높다는 게 현실입니다.
그런데 최근 AI 업계에서 아주 흥미로운 흐름이 나타나고 있습니다. "작지만 강한 AI", 즉 소형 언어모델(SLM, Small Language Model)이 급격히 성장하면서 기업들의 AI 도입 방정식을 완전히 바꾸고 있는 것이죠. Microsoft의 Phi 시리즈, Google의 Gemma, Meta의 Llama, 그리고 LG AI의 EXAONE까지 — 단 수십억 개의 파라미터로도 특정 작업에서 GPT-4에 버금가는, 심지어 뛰어넘는 성능을 보여주는 모델들이 속속 등장하고 있습니다.
비용은 GPT-4 대비 최대 100분의 1 수준, 심지어 스마트폰 안에서도 돌아가는 이 모델들이 정말 비즈니스에서 쓸 만한 수준일까요? 아니면 저렴한 대신 성능 타협을 감수해야 할까요? 이 글에서는 2024~2025년 최신 SLM 라인업의 벤치마크 데이터, 실제 활용 사례, 비용 비교 분석을 통해 여러분이 현명한 AI 전략을 세울 수 있도록 완벽하게 정리해 드리겠습니다. 📊
---

---
SLM이란 무엇인가? 경량 LLM의 기술적 정의와 등장 배경
SLM(Small Language Model, 소형 언어모델)은 일반적으로 파라미터 수가 10억(1B)에서 70억(7B) 수준의 언어 모델을 지칭합니다. 넓은 의미로는 30B 이하를 경량 LLM으로 분류하기도 합니다. GPT-4가 추정 1조 개 이상, GPT-3.5도 1,750억 개의 파라미터를 갖는 것과 비교하면 압도적으로 작은 규모입니다.
그렇다면 왜 지금 SLM이 주목받을까요? 핵심은 "작다고 무조건 못하지 않다"는 패러다임의 전환에 있습니다. 초기 소형 모델들은 성능 한계가 명확했지만, 2023년 이후 세 가지 기술 혁신이 SLM의 위상을 완전히 바꿔놨습니다.
첫째, 데이터 품질 혁명입니다. Microsoft Phi 시리즈의 연구팀이 처음 증명한 개념인데, '합성 데이터(synthetic data)'와 엄격히 큐레이션된 고품질 텍스트로 훈련하면 파라미터가 적어도 놀라운 추론 능력을 갖출 수 있다는 것입니다. Phi-1은 단 13억 파라미터로 기존 350억 파라미터 모델을 코딩 벤치마크에서 능가했습니다.
둘째, 양자화(Quantization) 기술의 발전입니다. INT4, GGUF, AWQ 등의 양자화 기법을 통해 모델 크기를 원래의 25~50% 수준으로 압축하면서도 성능 손실을 5% 미만으로 유지할 수 있게 됐습니다. 7B 모델도 양자화하면 일반 노트북(16GB RAM)에서 충분히 구동됩니다.
셋째, 특화 파인튜닝(Fine-tuning) 접근법입니다. 범용 능력보다는 특정 도메인에서의 전문성을 집중적으로 학습시키는 방식으로, 의료·법률·고객서비스 등 특정 영역에서는 GPT-4보다 우수한 성능을 내는 소형 모델도 등장했습니다.
온디바이스 AI 관점에서도 SLM의 중요성은 더욱 부각됩니다. 클라우드를 거치지 않고 디바이스 자체에서 AI 추론이 이뤄지면 개인정보 보호, 레이턴시 최소화, 인터넷 불필요, 지속적인 API 비용 제거라는 4가지 혁명적 이점이 생깁니다. 이것이 바로 SLM 열풍의 본질입니다.
---

---
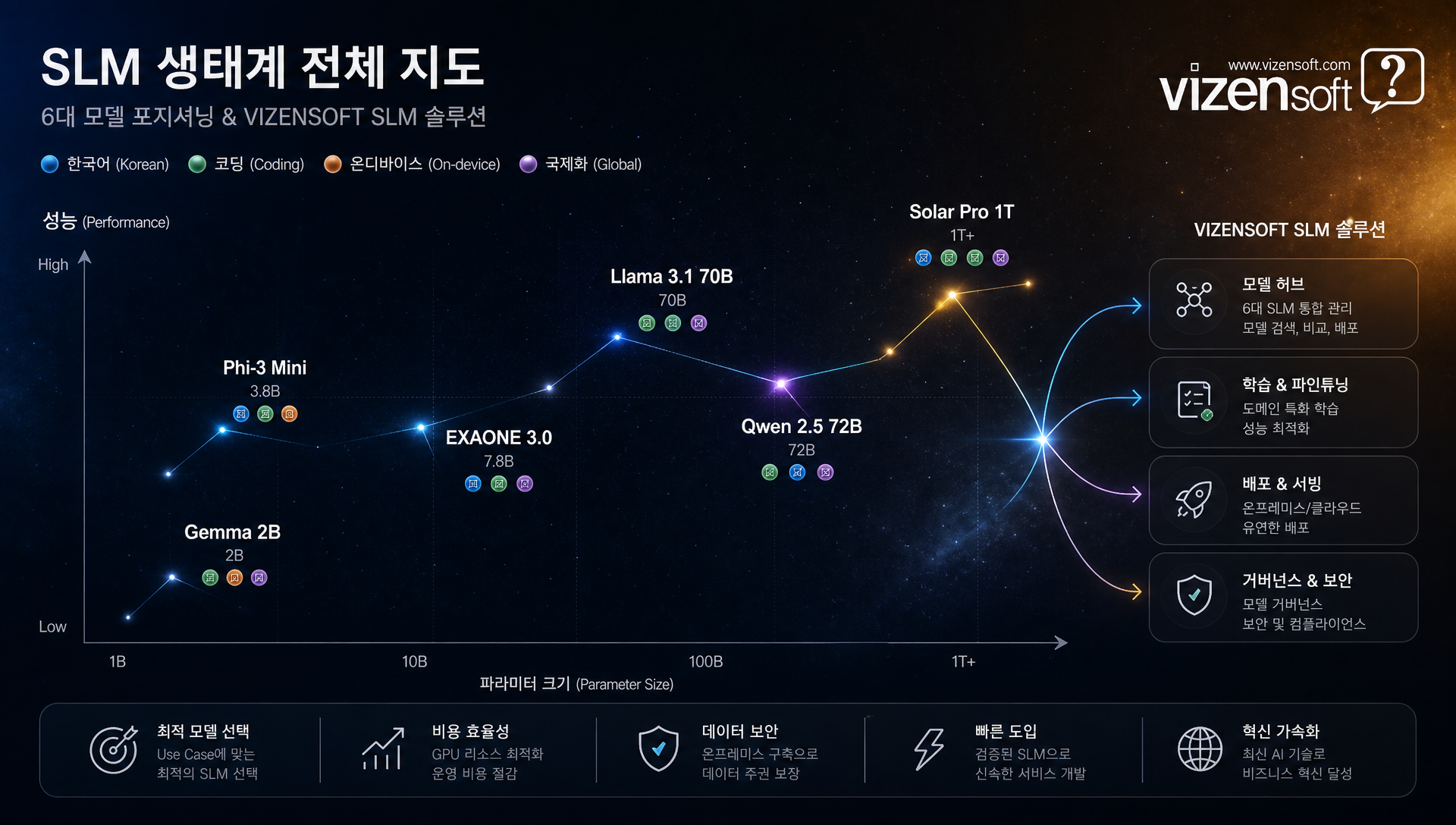
주요 SLM 라인업 완전 해부: Phi, Gemma, Llama, EXAONE의 실력은?
2024~2025년 현재 비즈니스에서 실제로 활용 가능한 대표 SLM 모델들을 상세히 분석해 보겠습니다. 단순 스펙 나열이 아닌, 실제 벤치마크 데이터를 기반으로 어떤 작업에 적합한지까지 살펴봅니다.
🔵 Microsoft Phi 시리즈 — 소형 모델의 새 지평
Microsoft Research가 개발한 Phi 시리즈는 SLM 혁명의 선봉장입니다. "작지만 가르칠수록 강해진다"는 철학으로 고품질 합성 데이터를 활용한 훈련 방식이 특징입니다.
Phi-3-mini (3.8B) 는 MMLU(Massive Multitask Language Understanding) 점수 68.8점, HumanEval 코딩 평가 60.8점을 기록하며, 이는 GPT-3.5 수준에 준하는 성능입니다. 특히 스마트폰에서 직접 구동이 가능하다는 점이 혁명적입니다. Qualcomm Snapdragon 8 Elite 칩 기반 안드로이드 폰에서 초당 20토큰 이상의 속도로 실행됩니다.
Phi-4 (14B) 는 2024년 12월 출시된 최신 모델로, MMLU 84.8점으로 GPT-4o-mini(82.0점)를 능가합니다. HumanEval 코딩 테스트에서는 82.6점으로 GPT-4 초기 버전(67점)을 크게 웃돌며 수학·추론 특화 성능에서 특히 두드러집니다. 140억 파라미터로 이 정도 성능을 낸다는 것은 업계에서도 충격적인 결과로 받아들여졌습니다.
🟢 Google Gemma 2 시리즈 — 스케일별 최적화
Google DeepMind가 공개한 Gemma 2는 2B/9B/27B 세 가지 사이즈로 제공되어 사용 목적에 맞는 선택이 가능합니다.
Gemma 2 2B 는 초경량 온디바이스용으로, 라즈베리파이 5 같은 저전력 임베디드 환경에서도 구동됩니다. MMLU 51.3점으로 절대적 점수는 낮지만, 비용 대비 성능비(Performance per Dollar)가 업계 최고 수준입니다.
Gemma 2 9B 가 가장 주목받는 모델입니다. MMLU 71.3점으로 Llama 3 8B(66.6점)보다 높고, 동급 모델 중 최고 성능을 자랑합니다. 특히 지시 따르기(Instruction Following) 능력이 뛰어나 RAG(검색 증강 생성) 시스템의 생성 모델로 탁월합니다.
Gemma 2 27B 는 준대형 모델 영역으로, MMLU 75.2점을 기록하며 단일 A100 GPU에서 구동 가능한 최강 성능 모델로 평가받습니다.
🟠 Meta Llama 3.2 시리즈 — 온디바이스 최적화의 완성
Meta의 Llama 3.2는 온디바이스 AI를 위해 처음부터 설계된 모델이라는 점에서 차별화됩니다. 1B와 3B 두 가지 경량 버전이 핵심입니다.
Llama 3.2 1B 는 MMLU 32.2점으로 성능보다 극한의 경량화에 초점을 맞춥니다. 메모리 사용량이 불과 0.5GB(INT4 양자화 시)로, IoT 디바이스, 구형 스마트폰, 마이크로컨트롤러 영역까지 적용 가능합니다.
Llama 3.2 3B 는 MMLU 58.0점으로 1B 대비 성능이 대폭 향상되었습니다. Apple Silicon(M1/M2/M3) 기반 맥에서 초당 60토큰 이상의 쾌적한 속도로 구동됩니다. Apple의 iPhone 16 시리즈에서 공식 활용되는 모델이기도 합니다.
🔴 LG AI EXAONE 2.4B — 한국어 특화 SLM의 강자
국내 기업 LG AI Research가 개발한 EXAONE 2.4B는 한국어 처리 능력에서 독보적인 위치를 차지합니다.
한국어 언어 이해 평가인 KMMLU(Korean MMLU) 점수 53.7점으로, 동급 외산 모델들(평균 35~42점)을 크게 앞섭니다. 특히 한국어 문장 구조의 복잡한 조사 처리, 존댓말 체계, 한국 고유 문화·법률·의료 용어에서 월등한 이해력을 보입니다.
금융, 의료, 법률 등 한국어 전문 용어가 많은 도메인에서 GPT-4 대비 한국어 응답 자연스러움 평가에서 더 높은 점수를 받는 경우도 있습니다. 국내 기업이 온프레미스 환경에서 데이터 보안을 유지하면서 AI를 도입하려 할 때 가장 현실적인 선택지입니다.
🟡 그 외 주목할 SLM들
Qwen 2.5 (Alibaba) 는 0.5B~72B까지 폭넓은 라인업을 제공하며, 특히 다국어 처리에서 강점을 보입니다. 중국어와 한국어를 포함한 20개 이상의 언어에서 고른 성능을 내며, 7B 모델의 MMLU 점수가 74.2점으로 동급 최강 수준입니다.
Solar Mini (Upstage) 는 국내 AI 스타트업 Upstage가 개발한 한국어 특화 소형 모델로, 10.7B 파라미터로 한국어 생성 품질에서 높은 평가를 받고 있습니다.
---

---
비용 비교 분석: GPT-4보다 정말 100배 저렴한가?
이제 가장 중요한 질문, 실제 비용 차이가 얼마나 나는지 구체적인 데이터로 살펴보겠습니다. "100배 저렴하다"는 말이 과장인지, 사실인지 검증해 보겠습니다. 💰
API 기준 추론 비용 비교
클라우드 API로 사용할 경우의 토큰당 비용을 비교하면 다음과 같습니다 (2025년 기준, 입력+출력 평균).
| 모델 | 파라미터 | 입력 비용($/1M tokens) | 출력 비용($/1M tokens) | GPT-4 대비 |
|---|---|---|---|---|
| GPT-4o | ~1.8T(추정) | $5.00 | $15.00 | 기준(1x) |
| GPT-4o mini | 소형 | $0.15 | $0.60 | ~1/20x |
| Phi-3 medium (14B) | 14B | $0.17 | $0.17 | ~1/50x |
| Gemma 2 9B | 9B | $0.10 | $0.10 | ~1/70x |
| Llama 3.2 3B | 3B | $0.06 | $0.06 | ~1/150x |
| 자체 호스팅 SLM | 3~14B | ~$0.01~0.05 | ~$0.01~0.05 | ~1/200x |
자체 호스팅(Self-hosting) 환경에서는 비용 차이가 더 극적입니다. AWS EC2 g4dn.xlarge 인스턴스(T4 GPU) 기준 시간당 약 $0.526으로, 7B 모델을 구동하면 시간당 약 500만 토큰 처리가 가능합니다. 이를 토큰당 비용으로 환산하면 $0.0001/1K tokens, GPT-4 대비 1,000배 이상 저렴합니다.
물론 인프라 구축·관리 비용과 엔지니어링 공수를 감안하면 단순 수치 비교는 어렵습니다. 하지만 월 1억 토큰 이상 처리하는 서비스라면 자체 SLM 호스팅의 ROI가 명확히 나옵니다.
응답 속도(Tokens/sec) 비교
비용만큼 중요한 것이 응답 속도입니다. 고객 대면 서비스라면 사용자 경험(UX)에 직결되는 요소죠.
| 환경 | 모델 | 속도(tokens/sec) | 지연시간(첫 토큰) |
|---|---|---|---|
| NVIDIA A100 GPU | Llama 3.2 3B | 180~250 | 0.1초 미만 |
| NVIDIA A100 GPU | Phi-4 14B | 80~120 | 0.2초 미만 |
| NVIDIA A100 GPU | GPT-4 급 (70B+) | 30~50 | 0.5~1초 |
| Apple M3 Pro | Llama 3.2 3B | 55~70 | 0.3초 미만 |
| 스마트폰(Snapdragon 8 Elite) | Phi-3-mini 3.8B | 20~30 | 0.5초 내외 |
| OpenAI API (GPT-4o) | — | 40~80 | 1~3초(네트워크 포함) |
SLM은 로컬 실행 시 GPT-4 API보다 첫 토큰 지연시간이 대폭 짧습니다. 네트워크 왕복 시간(RTT)이 없기 때문입니다. 이는 실시간 음성 인터페이스나 타이핑 중 자동완성 같은 응답성이 중요한 앱에서 결정적 강점입니다.
메모리 요구량 비교
| 모델 | 파라미터 | FP16 메모리 | INT4 양자화 | 실행 가능 환경 |
|---|---|---|---|---|
| Llama 3.2 1B | 1B | ~2GB | ~0.5GB | 스마트폰, 라즈베리파이 |
| Llama 3.2 3B / Phi-3-mini | 3~4B | ~6GB | ~2GB | 노트북, 미니PC |
| Gemma 2 9B / Llama 3 8B | 7~9B | ~16GB | ~5GB | 일반 워크스테이션 |
| Phi-4 / Qwen 2.5 14B | 14B | ~28GB | ~8GB | 전문가용 워크스테이션 |
| GPT-4급 (70B~) | 70B+ | 140GB+ | 40GB+ | 고성능 서버 필수 |
7B 이하 모델은 일반 16GB RAM 노트북에서도 INT4 양자화로 구동 가능합니다. 별도 GPU 서버 없이 오피스 PC나 미니PC(Mac mini, Intel NUC 등)에서 AI 서비스를 운영할 수 있다는 의미입니다.
---
---
SLM이 빛나는 최적 활용 영역: 어디에 쓰면 가장 효과적인가?
SLM이 무조건 GPT-4보다 못한 것도, 무조건 모든 상황에서 GPT-4를 대체할 수 있는 것도 아닙니다. 핵심은 "어떤 작업에 어떤 모델을 쓰느냐"의 아키텍처 설계입니다. SLM이 압도적인 효율을 내는 영역들을 구체적으로 살펴보겠습니다. 🎯
적합 작업 영역 ①: 분류·태깅·라우팅
텍스트를 특정 카테고리로 분류하거나, 감성 분석, 의도(Intent) 파악 같은 작업은 SLM의 전통적 강점입니다. 예를 들어 고객 문의를 "환불", "배송", "기술지원", "일반문의" 4개 카테고리로 분류하는 작업은 Phi-3-mini 3.8B로도 GPT-4 수준의 정확도(90% 이상)를 낼 수 있습니다.
비용 절감 효과가 가장 극적인 영역이기도 합니다. 하루 10만 건의 문의를 분류하는 서비스라면 GPT-4 API 대비 월 수천만 원 절약이 가능합니다.
적합 작업 영역
②: 요약(Summarization)
문서·뉴스·보고서 요약은 SLM이 특히 잘 하는 작업입니다. 입력 컨텍스트가 명확하고 창의적 생성보다 핵심 추출이 주 목표이기 때문입니다. RAG 파이프라인에서 검색된 문서를 요약하는 Retrieval Summarizer 역할에 Gemma 2 9B나 Llama 3.2 3B를 배치하면 비용을 획기적으로 줄일 수 있습니다.
적합 작업 영역
③: 번역 및 다국어 처리
특정 언어 쌍(예: 한영, 한중 번역)에 파인튜닝된 SLM은 번역 전문 영역에서 GPT-4와 동등하거나 더 나은 일관성을 보이기도 합니다. Qwen 2.5의 경우 아시아권 다국어 번역에서 특히 강점을 보이며, EXAONE은 한국어↔영어 번역의 자연스러움 평가에서 높은 점수를 받습니다.
적합 작업 영역
④: RAG 시스템의 핵심 부품
RAG(Retrieval-Augmented Generation) 파이프라인에서 SLM 활용은 가장 실용적인 접근법입니다. RAG는 크게 두 단계로 나뉩니다.
- 검색 단계(Retrieval): 사용자 질문과 관련된 문서를 벡터 DB에서 찾는 과정
- 생성 단계(Generation): 찾은 문서를 바탕으로 답변을 생성하는 과정
검색 단계의 리랭커(Reranker) 로 소형 BERT 계열 모델(~0.3B)이나 경량 SLM을 쓰고, 생성 단계에 Gemma 2 9B나 Phi-4를 쓰는 구성은 GPT-4 RAG 대비 비용의 10분의 1로 유사한 품질을 낼 수 있습니다.
적합 작업 영역
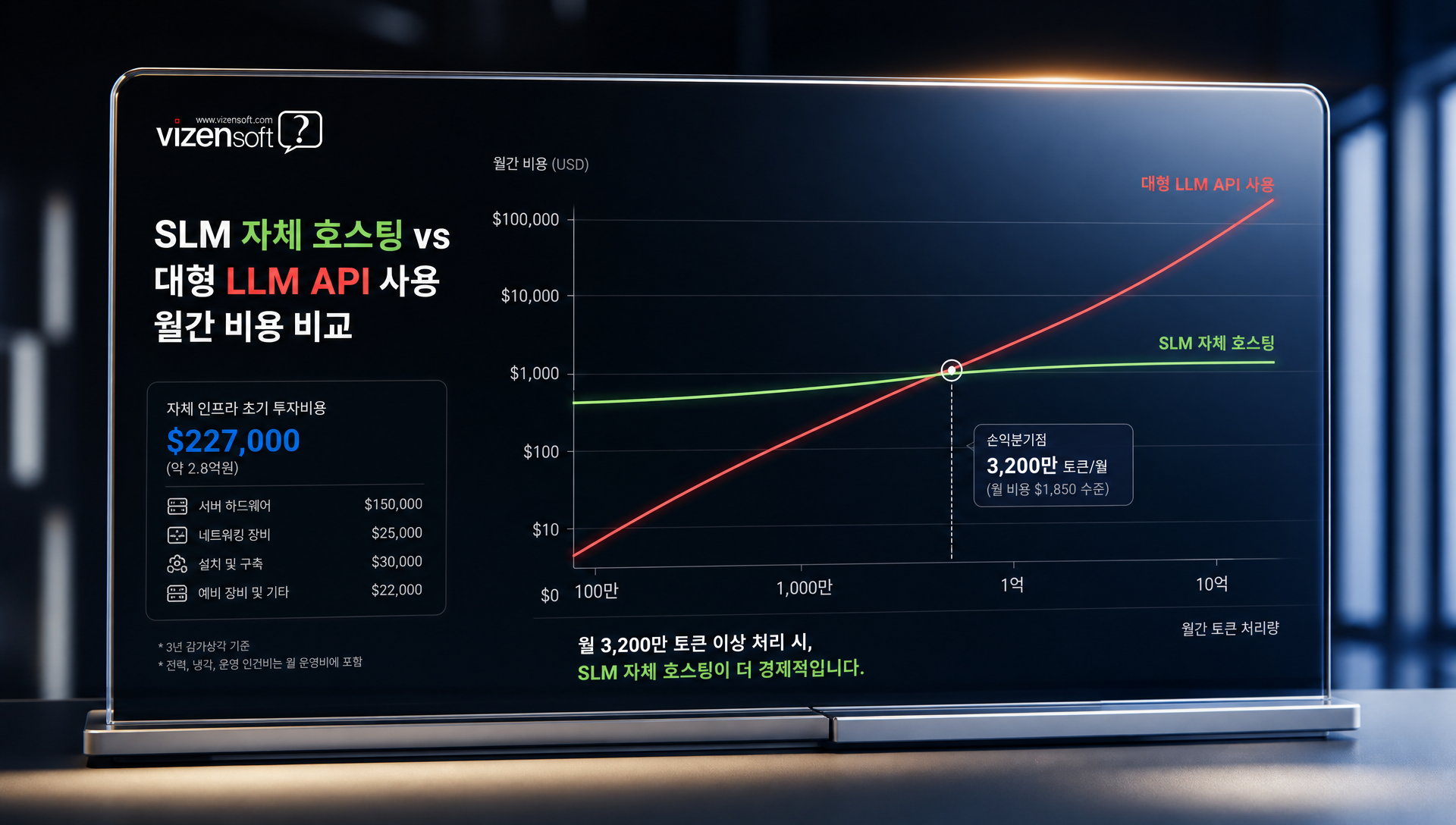
⑤: 1차 응답 + Fallback 아키텍처
가장 스마트한 아키텍처 설계 중 하나입니다. SLM이 1차 응답을 시도하고, 신뢰도가 낮거나 복잡한 요청에만 대형 모델로 Fallback하는 방식입니다.
- Step 1: 모든 요청을 Llama 3.2 3B 또는 Phi-3-mini가 1차 처리
- Step 2: 응답 신뢰도 점수(Confidence Score) 또는 복잡도 분류기가 평가
- Step 3: 신뢰도 높은 요청(70~80%) → SLM 응답 그대로 사용
- Step 4: 복잡한 요청(20~30%) → GPT-4o 또는 Claude로 Fallback
이 방식으로 전체 API 비용의 70~80%를 절감하면서도 최종 사용자가 체감하는 품질은 거의 동등하게 유지할 수 있습니다. 미국 주요 AI 스타트업들이 이 아키텍처를 채택해 서비스를 성공적으로 확장한 사례들이 다수 보고됐습니다.
---
---
온디바이스 AI 시장 트렌드와 SLM의 미래 전망
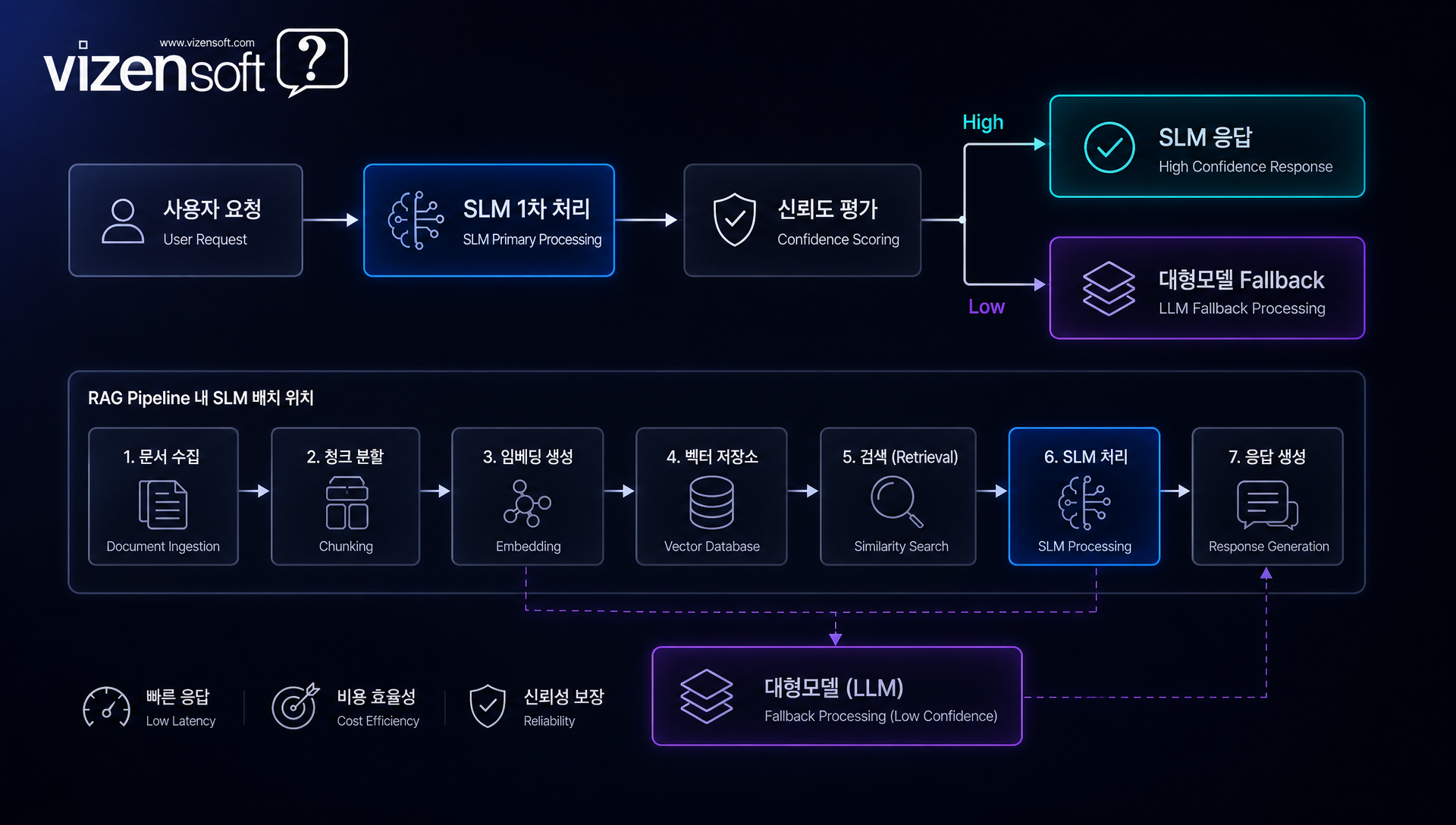
온디바이스 AI 시장은 폭발적 성장 궤도에 올라 있습니다. 글로벌 시장조사기관들의 2024~2025년 보고서에 따르면 온디바이스 AI 시장은 2023년 약 103억 달러에서 2030년 약 1,730억 달러로 연평균 성장률(CAGR) 50%를 넘는 초고속 성장이 예측됩니다. 📈
모바일·임베디드 분야의 SLM 적용 사례
스마트폰 영역이 가장 빠르게 움직이고 있습니다.
Apple은 iOS 18부터 Apple Intelligence라는 이름으로 기기 내장 AI를 도입했으며, 핵심 모델이 Llama 3.2 기반의 약 3B 파라미터 모델입니다. 사용자의 개인 데이터가 서버로 나가지 않고 iPhone 내에서 처리되는 것이 핵심 차별점입니다.
Samsung Galaxy S24 시리즈의 Galaxy AI 기능들도 온디바이스 경량 모델과 클라우드 모델을 선택적으로 활용하는 하이브리드 방식을 채택했습니다. 실시간 통화 번역, 문서 요약, 이미지 편집 등의 기능이 오프라인에서도 동작합니다.
산업용 임베디드 영역에서도 SLM 도입이 급증하고 있습니다.
- 제조업 현장의 산업용 태블릿에서 설비 매뉴얼 Q&A를 오프라인으로 처리
- 의료용 디바이스에서 환자 데이터를 외부 서버로 보내지 않고 현장 진단 보조
- 차량 내 인포테인먼트 시스템에서 인터넷 연결 없이 자연어 명령 처리
- 군사·보안 환경에서 인터넷이 차단된 상황에서의 AI 지원 시스템
2026년 SLM 트렌드 예측
AI 업계 전문가들이 공통적으로 지목하는 2026년 SLM 핵심 트렌드는 다음과 같습니다.
첫째, 멀티모달 경량 모델의 대중화입니다. 텍스트만 처리하는 기존 SLM에서 이미지, 오디오, 비디오를 함께 처리하는 멀티모달 SLM이 스마트폰 급 디바이스에서 동작하게 됩니다. Llama 3.2의 Vision 버전(11B/90B)이 그 예고편입니다.
둘째, AI 칩 생태계의 폭발적 확장입니다. Qualcomm, MediaTek, Apple Silicon, 그리고 국내 기업들의 NPU(신경망처리장치) 발전으로 스마트폰에서의 SLM 성능이 2배 이상 향상될 전망입니다.
셋째, 분야별 초특화 SLM의 등장입니다. 범용 SLM보다 의료·법률·금융 등 특정 도메인에만 집중한 1~3B 초소형 전문가 모델들이 기업용 시장에서 주목받을 것입니다.
넷째, 연합학습(Federated Learning) 기반 SLM이 개인정보 보호 규제가 강한 의료·금융 분야의 표준이 될 전망입니다. 각 사용자 기기에서 프라이버시를 지키며 모델을 개인화하는 방식입니다.
---
---
SLM vs LLM 완전 비교: 어떤 상황에서 무엇을 선택해야 할까?
이제 가장 실용적인 질문으로 넘어갑니다. 내 프로젝트에는 SLM을 써야 할까, 아니면 GPT-4 같은 대형 모델을 써야 할까? 이 의사결정을 도와드리는 종합 비교표를 정리했습니다. ⚖️
| 비교 항목 | 소형 언어모델 (SLM 3~14B) | 대형 언어모델 (LLM 70B~) |
|---|---|---|
| 추론 비용 | ★★★★★ (100배↓ 이상) | ★★☆☆☆ (고비용) |
| 응답 속도 | ★★★★★ (로컬 초고속) | ★★★☆☆ (API 지연 포함) |
| 메모리 요구 | ★★★★★ (2~28GB) | ★★☆☆☆ (140GB+) |
| 복잡한 추론 | ★★☆☆☆ (한계 있음) | ★★★★★ (탁월) |
| 창의적 생성 | ★★★☆☆ (제한적) | ★★★★★ (탁월) |
| 긴 문맥 처리 | ★★★☆☆ (모델 따라 다름) | ★★★★★ (128K+ 지원) |
| 한국어 특화 | ★★★★☆ (EXAONE 등) | ★★★★☆ (범용 우수) |
| 프라이버시 | ★★★★★ (온프레미스 가능) | ★★☆☆☆ (클라우드 의존) |
| 오프라인 사용 | ★★★★★ (가능) | ★☆☆☆☆ (API 필수) |
| 커스텀 파인튜닝 | ★★★★★ (쉽고 저렴) | ★★☆☆☆ (고비용·복잡) |
| 코딩 지원 (Phi-4) | ★★★★☆ (특화 모델 우수) | ★★★★★ (범용 최강) |
SLM 선택이 최적인 시나리오
- 월 API 비용이 100만 원 이상이면서 트래픽 증가에 대한 비용 부담이 있는 경우
- 고객 데이터, 의료 기록, 금융 정보 등 민감한 데이터를 외부 서버로 보낼 수 없는 경우
- 반복적·정형화된 작업(분류, 요약, 번역, 간단한 Q&A)이 전체 요청의 70% 이상인 경우
- 인터넷 연결이 불안정하거나 없는 환경 (현장, 군사, 의료기기, 차량 등)
- 빠른 응답 속도가 UX에 직결되는 실시간 서비스
LLM 유지가 더 나은 시나리오
- 복잡한 다단계 추론, 고차원 분석, 학술 논문 수준의 문서 작성
- 한 번도 본 적 없는 새로운 유형의 요청을 유연하게 처리해야 할 때
- 128K 토큰 이상의 극히 긴 문서를 단번에 처리해야 할 때
- 코딩 에이전트, 복잡한 멀티스텝 자동화 파이프라인
---

---
실전 활용 사례: 기업들은 SLM으로 어떤 변화를 이뤄냈나?
이론이 아닌 실제 현장에서 SLM이 어떤 비즈니스 가치를 만들어내는지 구체적인 사례를 살펴보겠습니다. 🏆
사례 ①: 국내 이커머스 기업 — 고객문의 자동화
국내 중견 이커머스 기업 A사는 일평균 3만 건의 고객 문의를 처리합니다. 기존에 GPT-3.5 API를 사용하던 챗봇 시스템의 월 API 비용은 약 1,200만 원이었습니다. 문의 유형 분류 + 1차 응답 생성 + 에스컬레이션 판단 세 단계 모두를 GPT-3.5에 의존하는 구조였습니다.
SLM 전환 프로젝트를 통해 Phi-3-mini 3.8B(INT4 양자화)를 자체 서버에 배치하고 다음과 같이 구조를 개편했습니다.
- 1단계: 분류·라우팅 → Phi-3-mini 처리 (전체의 85%)
- 2단계: 1차 응답 생성 → Phi-3-mini 처리 (전체의 65%)
- 3단계: 복잡한 민원·감성 대응 → 외부 LLM API Fallback (전체의 15%)
결과적으로 월 API 비용이 1,200만 원에서 220만 원으로 82% 감소했습니다. 자체 서버 운영비(월 80만 원)를 포함해도 순 절감액이 월 900만 원입니다. 응답 속도는 오히려 개선되어 평균 응답 시간이 2.3초에서 0.8초로 단축됐습니다.
사례
②: 법무법인 — 온프레미스 계약서 검토 시스템
대형 법무법인 B사는 AI 계약서 검토 시스템 도입을 검토했으나, 의뢰인의 기밀 정보가 포함된 계약서를 외부 클라우드 서버로 전송하는 것이 윤리적·법적으로 불가하다는 판단이 내려졌습니다.
EXAONE 2.4B를 기반으로 법률 계약서 수천 건을 파인튜닝 데이터로 활용해 온프레미스 특화 모델을 구축했습니다. 외부 인터넷 없이 사내 서버에서만 동작하며, 표준 계약서 조항 추출·위험 조항 하이라이팅·요약 작업에서 전문 법률 리뷰어 대비 1차 검토 시간 75% 단축 효과를 달성했습니다.
사례
③: 제조업 — 스마트팩토리 현장 AI
반도체 장비 기업 C사는 클린룸 환경에서 인터넷 연결이 불가능한 생산 현장에 AI 보조 시스템이 필요했습니다. Llama 3.2 3B를 전용 산업용 태블릿(Qualcomm 칩셋)에 탑재, 설비 매뉴얼 12,000페이지를 RAG DB화해 오프라인 Q&A 시스템을 구축했습니다.
현장 엔지니어가 장비 이상 시 즉시 자연어로 질문하면 평균 0.6초 내에 관련 매뉴얼과 대응 방법이 제시됩니다. 기존 매뉴얼 수동 검색 대비 평균 12분이 걸리던 문제 진단 시간이 2분 미만으로 단축됐습니다.
---

---
SLM 도입을 위한 실전 체크리스트 & 단계별 가이드
SLM 도입을 검토 중이시라면, 다음 체크리스트를 단계적으로 확인하세요. ✅
1단계: 현황 분석 및 적합성 평가
- 현재 AI API 월 비용이 50만 원을 초과하는가?
- 전체 AI 요청의 60% 이상이 분류·요약·번역·정형 응답 등 단순 작업인가?
- 데이터 보안/프라이버시 이슈로 외부 클라우드 전송이 제한되는가?
- 인터넷 연결 불안정 환경에서의 AI 사용이 필요한가?
- 응답 속도 개선(1초 미만)이 비즈니스 KPI에 직결되는가?
2단계: 모델 선택 기준 결정
| 조건 | 추천 모델 | 이유 |
|---|---|---|
| 한국어 품질 최우선 | EXAONE 2.4B, Solar Mini | 한국어 특화 훈련 |
| 코딩·수학 지원 | Phi-4 14B | 합성 데이터 특화 |
| 모바일/임베디드 | Llama 3.2 1B~3B | 극한 경량화 |
| 범용 고성능 | Gemma 2 9B, Qwen 2.5 7B | 성능·효율 균형 |
| 다국어 동시 처리 | Qwen 2.5 14B | 20개 언어 지원 |
3단계: 인프라 설계
- 클라우드 호스팅 vs 온프레미스 결정 (월 5,000만 토큰 이상이면 자체 호스팅 유리)
- 양자화 수준 결정: INT8(성능 우선) vs INT4(경량화 우선)
- 추론 엔진 선택: Ollama(개발·테스트), vLLM(프로덕션), llama.cpp(임베디드)
- GPU vs CPU 구동 결정 (7B 이하는 최신 CPU도 가능)
4단계: 파인튜닝 및 평가
- 도메인 특화 데이터 1,000~10,000건으로 LoRA/QLoRA 파인튜닝 수행
- A/B 테스트를 통해 기존 LLM 대비 품질 차이 정량 평가
- 인간 평가(Human Evaluation)와 자동화 벤치마크 병행
5단계: 운영 및 모니터링
- 응답 품질 자동 모니터링 시스템 구축
- Fallback 발생률 추적 및 임계값 최적화
- 정기적 모델 업데이트 및 재평가 스케줄링
---

---
도입 효과 & ROI: 숫자로 보는 SLM 전환의 가치
SLM 전략적 도입이 가져다주는 ROI를 핵심 지표로 정리합니다. 💹
비용 절감 효과는 가장 즉각적인 가치입니다. API 의존 구조에서 자체 SLM으로 전환한 기업들의 평균 AI 운영 비용 절감률은 60~85% 수준으로 보고됩니다. 초기 인프라 구축 비용(서버·엔지니어링)을 포함해도 대부분의 기업이 6~18개월 내 투자 회수가 가능합니다.
응답 속도 개선은 사용자 경험에 직접적인 영향을 미칩니다. 네트워크 레이턴시가 없는 온디바이스 또는 온프레미스 SLM은 클라우드 API 대비 첫 응답 시간이 평균 60~80% 단축됩니다.
데이터 보안 리스크 제거는 금융·의료·법률 기업에서 특히 중요합니다. 데이터 유출 사고 한 건의 평균 손실이 수십억 원에 달하는 점을 감안하면, 온프레미스 SLM의 보안 가치는 비용 절감을 뛰어넘습니다.
확장성(Scalability) 측면에서도 SLM은 탁월합니다. 트래픽이 10배 증가해도 API 비용이 10배 증가하는 종속 구조에서 벗어나, 서버를 추가하는 방식으로 선형적 비용 관리가 가능합니다.
---

---
자주 묻는 질문 (FAQ)
Q1. SLM은 파인튜닝 없이도 바로 쓸 수 있나요?
A. 네, 분류·번역·요약·간단한 Q&A 같은 범용 작업은 파인튜닝 없이 기본 모델(Base 또는 Instruct 버전)로도 즉시 활용 가능합니다. 다만 특정 도메인 전문 용어나 기업 내부 지식이 필요한 경우는 파인튜닝 또는 RAG 구성을 통해 성능을 끌어올리는 것이 효과적입니다.
Q2. GPU 없이 SLM을 운영할 수 있나요?
A. 7B 이하 모델은 INT4 양자화 시 CPU만으로도 구동 가능합니다. 다만 응답 속도가 GPU 대비 5~10배 느리므로 처리량이 적은 내부 도구나 배치 처리 용도에 적합합니다. 빠른 응답이 필요한 고객 대면 서비스는 GPU 또는 Apple Silicon 환경을 권장합니다.
Q3. 한국어 처리가 중요한데, 어떤 SLM이 가장 좋나요?
A. EXAONE 2.4B(LG AI)와 Solar Mini(Upstage)가 한국어 특화 SLM 중 최상위 수준입니다. 일반 영어 기반 SLM(Llama, Phi 등)도 한국어 처리는 되지만, 한국어 뉘앙스·전문 용어·높임말 처리에서 차이가 납니다. 한국어가 주요 언어라면 한국어 특화 모델이나 한국어 데이터로 파인튜닝된 모델을 선택하세요.
Q4. SLM으로 GPT-4 수준의 모든 작업을 대체할 수 있나요?
A. 모든 작업을 대체하기는 현재로서는 어렵습니다. 복잡한 다단계 추론, 창의적 글쓰기, 긴 문맥 처리 영역은 여전히 대형 모델이 우위입니다. 현실적인 전략은 "전면 대체"가 아닌 "전략적 배분"입니다. 전체 요청의 70~80%를 SLM으로 처리하고, 나머지 복잡한 요청만 대형 모델로 라우팅하는 하이브리드 아키텍처가 가장 효과적입니다.
Q5. SLM 도입에 얼마나 걸리나요?
A. 기존 서비스에 클라우드 기반 SLM API를 연결하는 가장 빠른 방법은 1~2주면 가능합니다. 온프레미스 자체 호스팅은 인프라 구축 포함 1~2개월, 도메인 파인튜닝까지 포함하면 2~4개월 내외입니다. 비젠소프트의 SLM 도입 컨설팅 서비스를 활용하면 초기 설계부터 프로덕션 배포까지의 기간을 크게 단축할 수 있습니다. 자세한 내용은 아래 서명 블록을 참고해 주세요.
---
마무리: "작은 AI"가 만드는 큰 변화, 지금이 전략을 세울 때입니다
SLM(소형 언어모델)은 단순히 "저렴한 GPT 대용품"이 아닙니다. 특정 영역에서는 대형 모델보다 더 빠르고, 더 안전하고, 더 효율적인 AI 솔루션입니다. GPT-4 대비 100배 저렴하다는 것이 과장처럼 들렸다면, 이 글을 통해 그것이 충분히 현실적인 숫자임을 확인하셨을 겁니다.
AI 비용의 장벽으로 도입을 망설였던 중소기업도, 데이터 보안 이슈로 클라우드 AI를 쓰지 못했던 금융·의료 기업도, 인터넷 없는 현장에 AI가 필요했던 제조업도 — SLM은 이 모든 상황에 현실적인 해답을 제시합니다.
Phi-4의 놀라운 추론 능력, EXAONE의 한국어 특화 강점, Llama 3.2의 온디바이스 최적화, Gemma 2의 효율적 균형감 — 지금 이 순간에도 SLM 생태계는 빠르게 발전하고 있습니다. 2026년을 향해 온디바이스 AI가 표준이 되는 시대, 지금 올바른 SLM 전략을 수립한 기업이 AI 경쟁에서 앞서나갈 것입니다. 🚀
비젠소프트는 SLM 모델 선택부터 인프라 설계, 파인튜닝, 프로덕션 배포까지 엔드투엔드 AI 솔루션을 제공합니다. AI 비용 절감과 온프레미스 구축을 고민하신다면 언제든지 아래 서명 블록을 통해 연락해 주세요.
---
---

---
🏢 VIZENSOFT(비젠소프트) | SLM·경량LLM·온디바이스AI 솔루션 전문
📧 | 🌐 www.vizensoft.com | 📞
AI 비용 절감과 온프레미스 AI 구축, 비젠소프트와 함께 시작하세요 🚀
🔗 https://www.vizensoft.com





