통찰력 있는 IT 기업 비젠소프트를 소개합니다.
-
통찰력 있는 사람들이 함께하는 젊고 열정적인 IT 기업, 비젠소프트.
A young and passionate technology company,
brought together by people with keen insight—this is Vizensoft. -

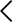 Back
Back머신러닝 vs 딥러닝, AI모델 목적에 맞는 방법은 따로 있다?
머신러닝 vs 딥러닝, AI모델 목적에 맞는 방법은 따로 있다? - "AI 도입은 했는데, 정작 비즈니스 성과는 생각보다 크지 않았어요."

# 머신러닝 vs 딥러닝, AI 모델 목적에 맞는 방법은 따로 있다? 🤖
"우리 회사에 맞는 AI, 머신러닝일까요 딥러닝일까요?" — 수백만 원짜리 AI 프로젝트 실패를 막는 핵심 질문
---
🚨 "AI 도입했는데 왜 성과가 안 나지?" — 수많은 기업이 반복하는 치명적 실수
"AI 도입은 했는데, 정작 비즈니스 성과는 생각보다 크지 않았어요."
이런 이야기, 한 번쯤 들어보셨거나 직접 경험해보신 분들이 많으실 겁니다. 실제로 글로벌 컨설팅 기관의 조사에 따르면, AI 프로젝트의 약 85%가 기대했던 비즈니스 가치를 달성하지 못하고 실패하거나 중단된다고 합니다. 수천만 원, 혹은 수억 원의 예산을 투입했음에도 불구하고 말이죠. 도대체 왜 이런 일이 반복되는 걸까요?
가장 큰 원인 중 하나는 놀랍도록 단순합니다. "목적에 맞지 않는 AI 방법론을 선택했기 때문" 입니다. 예를 들어, 고객 이탈 예측이라는 명확하고 구조적인 문제를 풀어야 하는데 값비싼 딥러닝 모델을 구축하다가 개발 기간과 비용이 폭발적으로 늘어난다든지, 반대로 수만 장의 의료 이미지에서 병변을 탐지해야 하는 과제에 단순한 머신러닝 알고리즘을 적용해서 정확도가 한참 모자라다든지 하는 상황이 실제 현업에서 비일비재하게 발생하고 있습니다.
중견 제조업체 A사의 사례를 보겠습니다. A사는 생산라인 불량률을 낮추기 위해 AI를 도입하기로 했고, "AI라면 딥러닝이 최고"라는 막연한 인식 아래 딥러닝 기반 비전 검사 시스템을 구축하려 했습니다. 하지만 실제로 보유한 불량 이미지 데이터는 고작 300여 장. 딥러닝이 제대로 학습하려면 통상 수만 장 이상의 데이터가 필요한데, 턱없이 부족한 상황이었죠. 결국 6개월간의 개발 기간과 수억 원의 비용을 쏟아부었지만 모델 정확도는 기대치의 절반에도 미치지 못했고, 프로젝트는 사실상 실패로 끝났습니다.
반면 같은 문제를 머신러닝 기반 이상 탐지 알고리즘으로 접근한 경쟁사 B사는 3개월 만에 불량률을 23% 감소시키는 성과를 냈습니다. 데이터 규모와 문제의 성격에 맞는 방법론을 선택했기 때문입니다.
이 글에서는 머신러닝과 딥러닝의 핵심 차이부터 시작해서, 어떤 비즈니스 목적에 어떤 AI 방법론이 최적인지를 구체적인 사례와 함께 명확하게 설명해 드립니다. 더불어 AI 모델 개발 전문 기업 비젠소프트가 실제 프로젝트에서 어떻게 최적 방법론을 선택하고 성과를 만들어내는지도 함께 소개할 예정입니다. 이 글 하나로 머신러닝과 딥러닝에 대한 혼란을 완전히 정리하시고, 여러분의 비즈니스에 맞는 AI 전략을 세울 수 있게 되실 겁니다. 🎯
---
🔍 머신러닝과 딥러닝, 도대체 뭐가 다른 건가요? — 핵심 개념 완전 정복
인공지능(AI), 머신러닝, 딥러닝은 뉴스와 마케팅 자료에서 거의 같은 의미로 혼용되곤 하지만, 실제로는 명확한 계층 구조를 가진 서로 다른 개념입니다. 이 차이를 이해하는 것이 올바른 AI 전략 수립의 첫걸음입니다.
쉽게 비유하자면, AI는 '자동차 산업' 전체라고 할 수 있습니다. 그 안에서 머신러닝은 '가솔린/디젤 엔진 자동차', 딥러닝은 '전기차' 정도로 이해하시면 됩니다. 전기차가 더 진보한 기술인 것은 맞지만, 그렇다고 해서 장거리 화물 운송에 가솔린 트럭 대신 전기 스포츠카를 쓰는 게 좋은 선택이 될 수는 없는 것처럼, AI 방법론도 목적과 환경에 따라 최적 선택이 달라집니다.
머신러닝(Machine Learning)은 데이터로부터 규칙과 패턴을 자동으로 학습하는 알고리즘의 집합입니다. 의사결정 트리(Decision Tree), 랜덤 포레스트(Random Forest), 서포트 벡터 머신(SVM), 그래디언트 부스팅(XGBoost, LightGBM) 등이 대표적인 머신러닝 알고리즘입니다. 핵심 특징은 사람이 직접 특징(Feature)을 추출하고 선택해서 모델에 입력한다는 점입니다. 예를 들어 고객 이탈 예측을 한다면, 데이터 분석가가 '최근 로그인 일수', '구매 금액 변화율', '고객센터 문의 횟수' 같은 의미 있는 변수를 직접 설계해서 모델에 넣어주는 방식입니다.
딥러닝(Deep Learning)은 머신러닝의 한 분야로, 인간의 뇌 신경망 구조를 모방한 인공 신경망(Artificial Neural Network) 을 여러 층(Layer)으로 깊게 쌓아 만든 모델입니다. 딥러닝의 가장 큰 혁신은 특징 추출 자체를 모델이 스스로 학습한다는 것입니다. 이미지를 보여주면 모델이 알아서 '이 픽셀 패턴이 눈이구나', '이 텍스처가 피부구나'를 스스로 파악합니다. 덕분에 이미지, 음성, 자연어처럼 사람이 직관적으로 이해하는 비정형 데이터에서 압도적인 성능을 발휘합니다.
결정적인 차이를 한 문장으로 요약하면 이렇습니다. "머신러닝은 사람이 특징을 설계하고, 딥러닝은 모델이 특징을 스스로 발견한다." 이 차이가 데이터 요구량, 연산 자원, 해석 가능성, 개발 난이도에서 엄청난 파급 효과를 만들어냅니다.

---
⚙️ 머신러닝의 진짜 강점 — 구조화된 데이터와 해석 가능한 예측 모델
많은 분들이 딥러닝이 머신러닝보다 무조건 뛰어나다고 생각하시는데, 이는 명백한 오해입니다. 구조화된 데이터(Structured Data) 환경에서는 머신러닝이 딥러닝보다 훨씬 뛰어난 성능과 효율을 보여주는 경우가 많습니다. 실제로 캐글(Kaggle)의 데이터 사이언스 경진대회에서도 정형 데이터 과제는 XGBoost나 LightGBM 같은 머신러닝 알고리즘이 우승을 차지하는 경우가 압도적으로 많습니다.
머신러닝이 빛나는 상황들을 구체적으로 살펴보겠습니다.
① 고객 이탈 예측 및 CRM 분석
고객의 구매 이력, 접속 패턴, 상담 기록, 인구통계 정보 같은 정형 데이터를 기반으로 이탈 가능성을 예측하는 과제입니다. 로지스틱 회귀나 랜덤 포레스트 모델이 탁월한 성능을 보이며, 어떤 변수가 이탈에 영향을 미치는지 설명 가능한 인사이트를 제공합니다. 이는 영업팀이나 마케팅팀이 실제 액션을 취하는 데 직접적으로 활용됩니다.
② 금융 신용 평가 및 리스크 관리
대출 승인 여부 판단, 사기 거래 탐지, 신용 점수 산출 등에 머신러닝이 광범위하게 활용됩니다. 특히 금융 규제 환경에서는 모델의 의사결정 근거를 설명해야 하는 XAI(설명 가능한 AI) 요건이 중요한데, 머신러닝은 딥러닝 대비 훨씬 높은 해석 가능성을 제공합니다.
③ 제조업 예측 정비(Predictive Maintenance)
기계 센서 데이터(진동, 온도, 압력 등)를 분석해서 장비 고장을 사전에 예측하는 과제입니다. 수십 개의 센서 변수로 구성된 정형 시계열 데이터에서 그래디언트 부스팅 계열 알고리즘이 매우 높은 정확도를 달성합니다.
④ 의료 진단 보조 (정형 검사 데이터)
혈액 검사 수치, 바이탈 사인, 처방 이력 같은 정형 의료 데이터를 기반으로 질병 위험도를 예측하는 모델입니다.
머신러닝의 핵심 비즈니스 가치는 세 가지로 정리됩니다.
첫째, 낮은 데이터 요구량 — 수천~수만 건의 데이터로도 충분히 학습 가능합니다.
둘째, 낮은 연산 비용 — 고가의 GPU 클러스터 없이도 일반 서버에서 학습 및 추론이 가능합니다.
셋째, 높은 해석 가능성 — 모델이 왜 이런 예측을 했는지 설명할 수 있어 비즈니스 의사결정에 바로 활용 가능합니다.
비젠소프트의 실제 프로젝트 경험에 따르면, 데이터 규모가 10만 건 미만이고 변수가 명확히 정의된 정형 데이터 문제라면 머신러닝이 딥러닝 대비 평균 40~60%의 개발 비용 절감과 더불어 오히려 더 높은 예측 정확도를 달성하는 경우가 많습니다. 무조건 최신 기술을 쫓기보다, 문제에 맞는 최적 도구를 선택하는 것이 훨씬 현명한 전략입니다.

---
🧠 딥러닝의 진짜 강점 — 비정형 데이터와 인간 수준의 패턴 인식
딥러닝은 2012년 이미지넷(ImageNet) 경진대회에서 컨볼루션 신경망(CNN)이 기존 방법론을 압도하는 성능을 보이면서 세상의 주목을 받기 시작했습니다. 이후 자연어 처리, 음성 인식, 생성 AI 등 수많은 분야에서 인간 수준을 뛰어넘는 성능을 달성하며 AI 혁명의 핵심 엔진으로 자리잡았습니다. 딥러닝의 진짜 강점은 사람이 손으로 특징을 추출하기 불가능한 복잡하고 비정형적인 데이터에서 발휘됩니다.
딥러닝이 압도적 성능을 보이는 핵심 영역들을 살펴보겠습니다.
① 컴퓨터 비전 (Computer Vision)
이미지와 영상에서 객체를 탐지하고 분류하는 과제입니다. 제조 품질 검사, 의료 영상 판독, 자율주행 차량의 도로 인식, 얼굴 인식 보안 시스템 등이 여기에 해당합니다. CNN(합성곱 신경망) 기반 모델들은 수천만 장의 이미지 데이터로 학습하여 숙련된 의사나 검사원 수준 이상의 정확도를 달성합니다. 실제로 피부암 진단 AI가 피부과 전문의보다 높은 정확도를 보인 연구 결과는 이미 학계에서 잘 알려져 있습니다.
② 자연어 처리 (NLP)
ChatGPT로 대표되는 대형 언어 모델(LLM)이 바로 딥러닝의 산물입니다. 고객 상담 챗봇, 문서 자동 분류, 감성 분석, 계약서 자동 검토, 다국어 번역 등 언어 관련 모든 AI 과제에서 트랜스포머(Transformer) 기반 딥러닝 모델이 표준으로 자리잡았습니다.
③ 음성 인식 및 합성
콜센터 음성 데이터 분석, AI 상담원, 음성 명령 인터페이스 구축에는 RNN, LSTM, 트랜스포머 기반 딥러닝 모델이 필수입니다.
④ 시계열 이상 탐지 (복잡한 패턴)
전통적인 통계 방법이나 단순 머신러닝으로 잡기 어려운 복잡한 비선형 시계열 패턴(주식 이상 거래, 사이버 보안 침해 탐지 등)에서 LSTM이나 Autoencoder 기반 딥러닝이 훨씬 뛰어난 성능을 발휘합니다.
딥러닝을 선택할 때 반드시 고려해야 할 현실적 요건도 있습니다.
첫째, 대규모 데이터 — 이미지 분류라면 최소 수만 장, 일반적으로 수십만 장 이상의 학습 데이터가 필요합니다.
둘째, 고성능 GPU 인프라 — 딥러닝 학습에는 고가의 GPU(NVIDIA A100 기준 장당 수천만 원)가 필요합니다.
셋째, 긴 개발 기간과 높은 전문성 — 모델 아키텍처 설계, 하이퍼파라미터 튜닝, 학습 안정화 등 고도의 전문 지식이 필요합니다.
넷째, 낮은 해석 가능성 — "왜 이런 결론을 내렸나"를 설명하기 어려운 블랙박스 특성이 있습니다.
비젠소프트는 이미지 기반 품질 검사, 자연어 기반 문서 분류, 복합 패턴 이상 탐지 프로젝트에 딥러닝을 적극 활용하며, 데이터 증강(Data Augmentation) 및 전이 학습(Transfer Learning) 기법으로 데이터 부족 문제를 효율적으로 극복하고 있습니다.

---
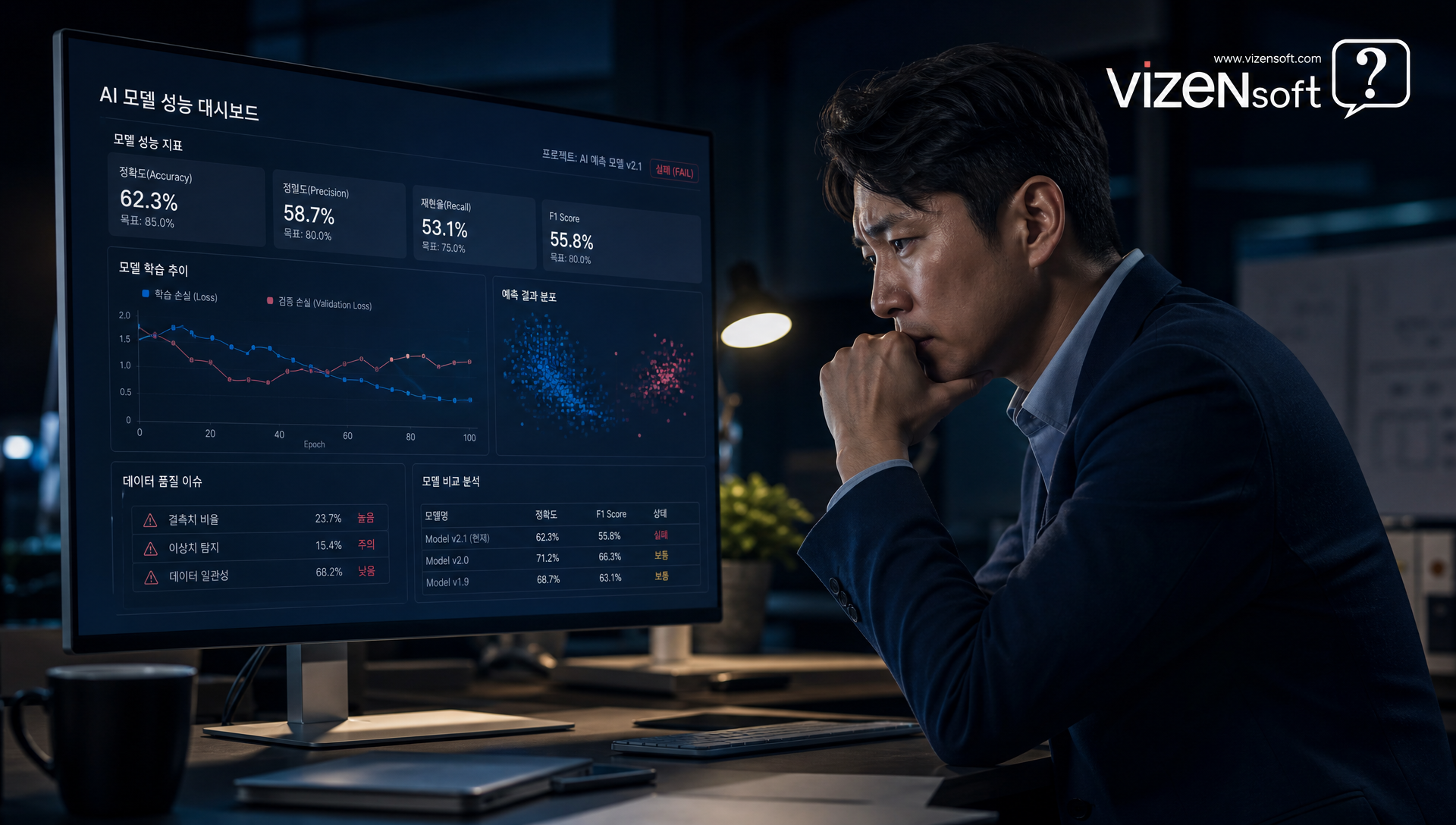
🎯 AI 모델 선택의 5가지 황금 기준 — 이걸 모르면 수억 원이 날아간다
머신러닝과 딥러닝 중 무엇을 선택해야 하는지 결정하는 것은 단순히 "더 최신 기술이 좋다"는 논리로 접근하면 절대 안 됩니다. 비즈니스 목적, 데이터 현황, 예산, 기간, 운영 환경이라는 5가지 황금 기준을 체계적으로 검토해야 합니다. 비젠소프트가 실제 고객사 AI 프로젝트에서 활용하는 방법론 선택 프레임워크를 공개합니다.
기준 1️⃣ : 데이터의 형태와 규모
가장 중요한 기준입니다. 데이터를 두 가지 축으로 분류해야 합니다.
- 정형 데이터(표 형태, 숫자/범주형) + 데이터 10만 건 미만 → 머신러닝 강력 추천
- 정형 데이터 + 데이터 수백만 건 이상 + 복잡한 비선형 패턴 → 딥러닝 또는 하이브리드 검토
- 비정형 데이터(이미지/텍스트/음성/영상) → 딥러닝 필수
- 데이터가 극히 부족(수백~수천 건) → 전이 학습 기반 딥러닝 또는 머신러닝 + 피처 엔지니어링
기준 2️⃣ : 문제의 성격과 복잡도
- 명확히 정의된 예측 문제 (이탈/불량/수요 예측) → 머신러닝 우선
- 패턴이 극도로 복잡하고 비선형적인 문제 → 딥러닝 검토
- 인간 지각 영역의 문제 (보고 듣고 읽는 것) → 딥러닝 필수
기준 3️⃣ : 설명 가능성(Explainability) 요건
- 금융·의료·법무처럼 의사결정 근거를 반드시 설명해야 하는 규제 산업 → 머신러닝 우선 (딥러닝 사용 시 별도 XAI 프레임워크 필요)
- 성능만 중요하고 설명이 불필요한 영역 → 딥러닝 가능
기준 4️⃣ : 예산과 인프라
- 초기 투자 최소화, 일반 서버 환경 → 머신러닝 적합
- 충분한 GPU 인프라 예산 및 클라우드 환경 → 딥러닝 가능
기준 5️⃣ : 개발 기간과 유지보수
- 3개월 이내 빠른 MVP(최소 기능 제품) 출시 필요 → 머신러닝 적합
- 장기 투자 가능, 지속적 모델 개선 계획 → 딥러닝 또는 하이브리드
비젠소프트는 이 5가지 기준을 기반으로 한 'AI 방법론 적합성 진단 체계' 를 통해 고객사 상황에 맞는 최적 방법론을 제안하고 있습니다. "무조건 딥러닝"도, "무조건 머신러닝"도 아닌, 데이터와 비즈니스 목적에 최적화된 솔루션 설계가 핵심입니다.
---
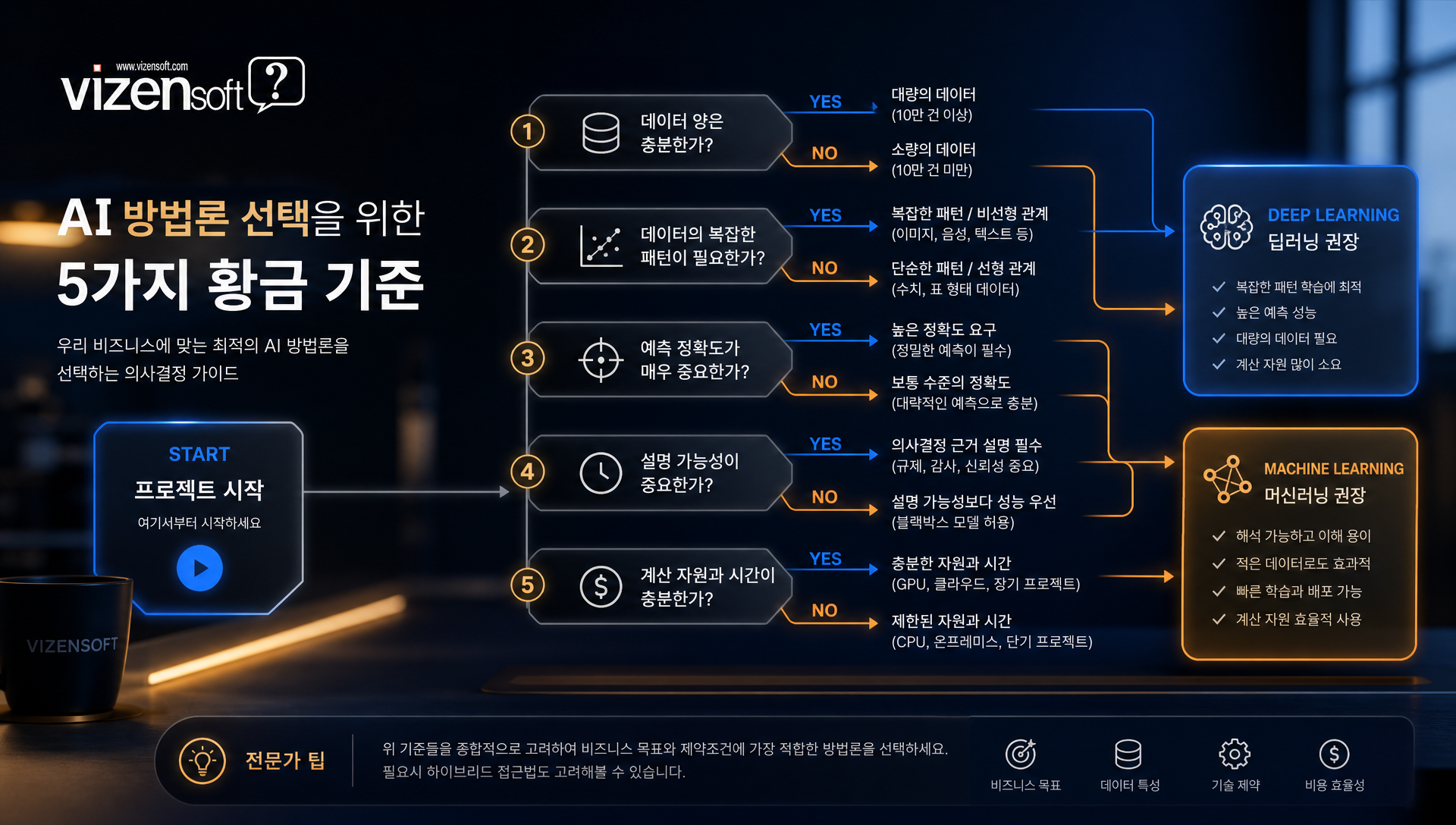
📊 2024~2025 AI 모델 개발 트렌드 — 지금 업계에서는 무슨 일이 일어나고 있나?
AI 모델 개발 트렌드는 2024년을 기점으로 "순수 딥러닝 vs 머신러닝"의 이분법적 구도를 넘어서는 방향으로 빠르게 진화하고 있습니다. 현재 업계의 핵심 흐름을 정리하면 다음과 같습니다.
트렌드 1. AutoML과 소형 고성능 모델의 급부상
거대 언어 모델(LLM)에 대한 열풍이 가라앉으면서, 실제 비즈니스 현장에서는 AutoML(자동화 머신러닝) 과 소형·경량 AI 모델에 대한 수요가 폭발적으로 증가하고 있습니다. 구글의 AutoML, 마이크로소프트의 Azure AutoML 등을 통해 데이터 과학 비전문가도 수준 높은 예측 모델을 구축할 수 있게 되었으며, 이는 중소기업의 AI 도입 장벽을 획기적으로 낮추고 있습니다.
트렌드 2. 하이브리드 AI 아키텍처의 표준화
머신러닝과 딥러닝을 결합한 하이브리드 아키텍처가 산업 현장에서 빠르게 표준이 되어가고 있습니다. 예를 들어, 딥러닝으로 비정형 데이터(이미지, 텍스트)에서 고차원 특징을 추출한 후, 이를 머신러닝 분류기에 입력하는 방식입니다. 이 조합은 양쪽의 장점(딥러닝의 강력한 특징 추출 + 머신러닝의 해석 가능성과 효율성)을 동시에 활용할 수 있습니다.
트렌드 3. 엣지 AI와 온디바이스 인퍼런스
클라우드 서버에서 돌아가던 AI 모델이 스마트폰, 제조 현장 엣지 디바이스, IoT 센서 단에서 직접 실행되는 엣지 AI 트렌드가 확산되고 있습니다. 이는 실시간성과 데이터 보안 요건이 강한 제조, 의료, 보안 분야에서 특히 주목받고 있으며, 모델 경량화(Quantization, Pruning) 기술의 중요성이 급증하고 있습니다.
트렌드 4. Foundation Model의 파인튜닝 전략
GPT, BERT, CLIP 같은 대형 사전 학습 모델을 기업 내 소량의 도메인 데이터로 파인튜닝(Fine-tuning) 하는 전략이 AI 도입의 가장 현실적인 접근법으로 부상하고 있습니다. 비젠소프트도 이 방식을 적극 활용하여 고객사별 특화 AI 솔루션을 효율적으로 개발하고 있습니다. 이 트렌드는 사실상 딥러닝 모델을 머신러닝처럼 적은 데이터와 짧은 기간으로 적용 가능하게 만드는 패러다임 전환입니다.
---
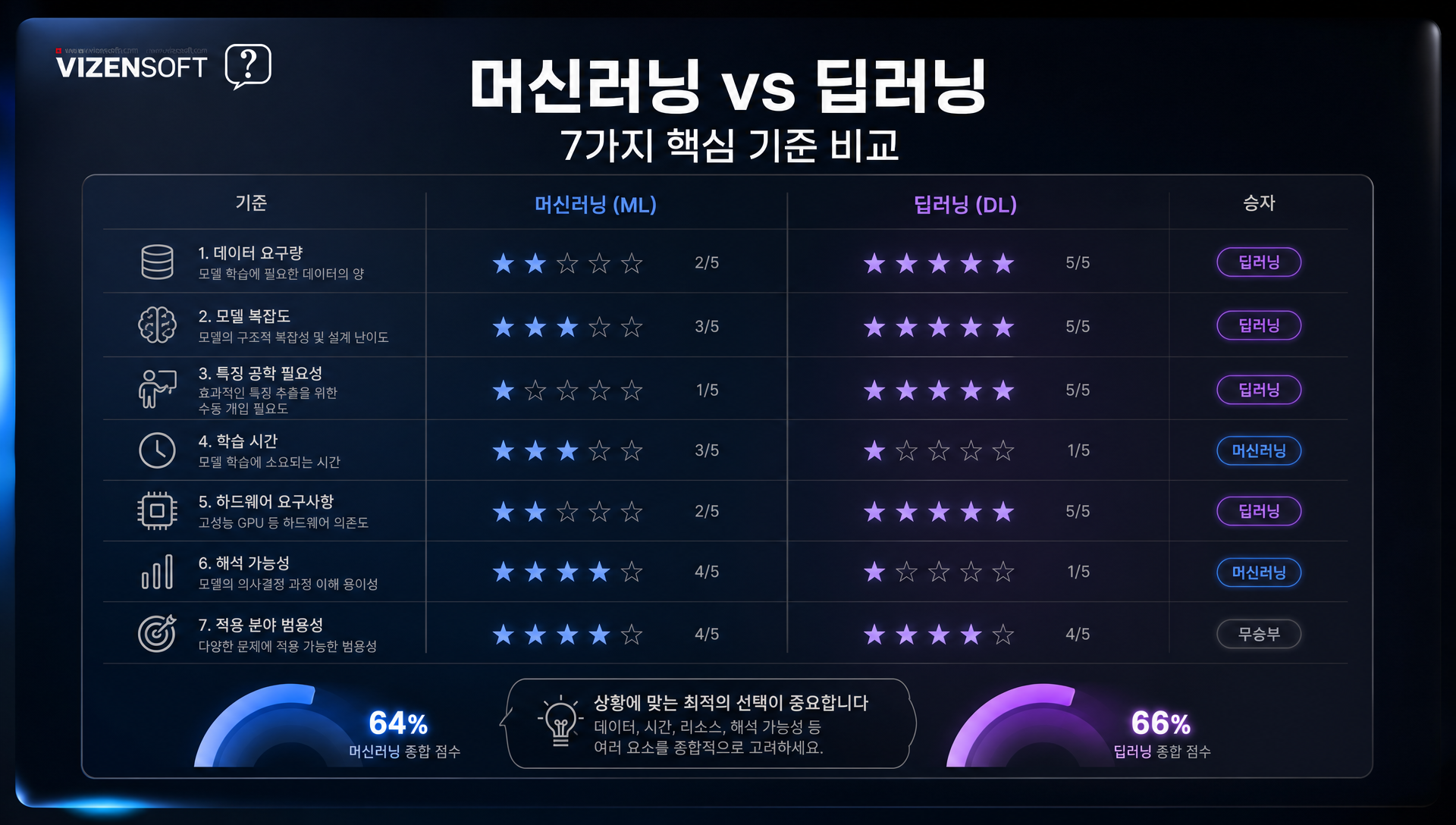
📋 머신러닝 vs 딥러닝 완전 비교표 — 한 눈에 정리하는 핵심 차이
지금까지 설명한 내용을 체계적으로 정리하기 위해, 7가지 핵심 기준으로 머신러닝과 딥러닝을 완전 비교해보겠습니다.
| 비교 기준 | 머신러닝 (ML) | 딥러닝 (DL) |
|---|---|---|
| 특징 추출 방식 | 사람이 직접 설계 (도메인 지식 필요) | 모델이 자동으로 학습 |
| 필요 데이터 규모 | 수천~수만 건으로 충분 | 수만~수백만 건 이상 권장 |
| 연산 자원 | CPU 기반 일반 서버 가능 | 고가 GPU 클러스터 필수 |
| 개발 기간 | 1~3개월 (빠른 MVP 가능) | 3~12개월 이상 |
| 설명 가능성 | 높음 (화이트박스 모델 많음) | 낮음 (블랙박스, XAI 별도 필요) |
| 최적 데이터 유형 | 정형 데이터 (표, 수치, 범주형) | 비정형 데이터 (이미지, 텍스트, 음성) |
| 비용 (개발+운영) | 상대적으로 저비용 | 상대적으로 고비용 |
다음으로, 비즈니스 목적별로 어떤 방법론이 더 적합한지를 정리한 두 번째 비교표입니다.
| 비즈니스 과제 | 권장 방법론 | 이유 |
|---|---|---|
| 고객 이탈 예측 | 머신러닝 (XGBoost, Random Forest) | 정형 데이터, 적은 데이터, 설명 가능성 중요 |
| 이미지 품질 검사 | 딥러닝 (CNN, Vision Transformer) | 비정형 이미지 데이터, 복잡한 패턴 |
| 수요/판매량 예측 | 머신러닝 + 딥러닝 (하이브리드) | 정형 시계열 + 외부 변수 복합 |
| 문서 분류·감성 분석 | 딥러닝 (BERT, Transformer) | 자연어 비정형 데이터 |
| 사기 거래 탐지 | 머신러닝 (그래디언트 부스팅) | 정형 금융 데이터, 규제 설명 요건 |
| 챗봇·상담 자동화 | 딥러닝 (LLM 파인튜닝) | 자연어 이해 및 생성 |
| 예측 정비 (센서 데이터) | 머신러닝 or 경량 딥러닝 | 정형 시계열, 실시간 엣지 처리 |
이 비교표에서 가장 중요한 인사이트는 "딥러닝이 언제나 더 좋은 것이 아니라, 문제에 최적화된 방법론이 최고" 라는 점입니다. 실제로 비즈니스 현장에서 발생하는 과제의 약 60~70%는 여전히 머신러닝으로 충분히, 그리고 더 효율적으로 해결 가능합니다.
---
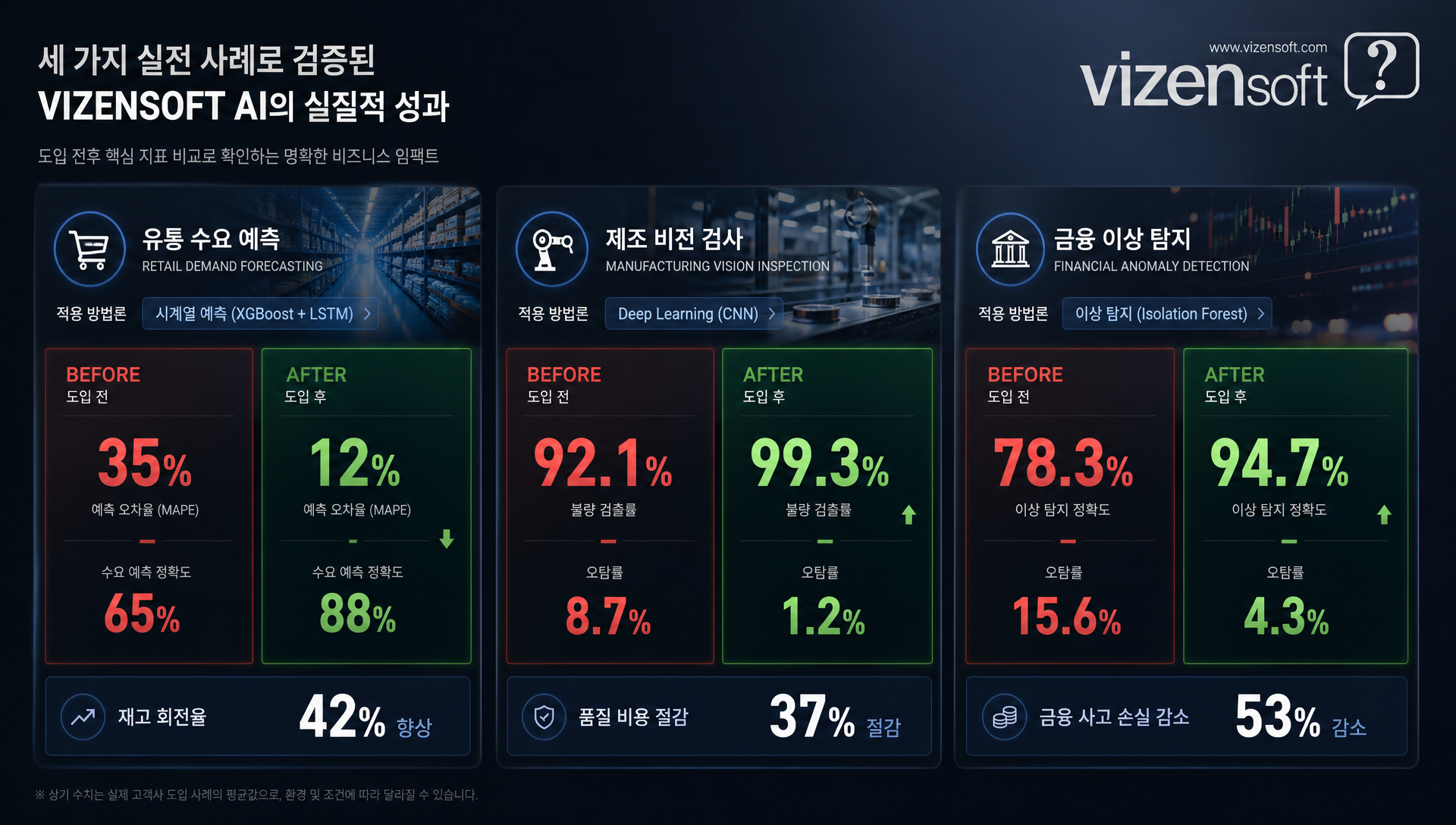
🏆 실전 성공 사례 — 비젠소프트가 만든 AI 모델 개발 성과
추상적인 이론보다 실제 성과가 더 설득력 있습니다. 비젠소프트가 다양한 산업에서 진행한 AI 모델 개발 프로젝트의 실전 사례를 소개합니다.
사례 1. 유통 대기업 — 수요 예측 모델 구축 (머신러닝 + 하이브리드)
국내 중견 유통 기업은 재고 과잉과 품절 손실이 동시에 발생하는 문제로 연간 수십억 원의 손실이 발생하고 있었습니다. 비젠소프트는 3년치 판매 이력, 날씨 데이터, 프로모션 정보, 경쟁사 가격 데이터 등 다양한 정형 데이터를 통합한 LightGBM 기반 수요 예측 모델을 구축했습니다.
- 결과: 수요 예측 정확도 MAPE(평균 절대 오차율) 기준 기존 대비 34% 향상
- 재고 보유 비용 18% 절감, 품절로 인한 매출 손실 22% 감소
- 프로젝트 기간: 약 4개월 / ROI 달성 기간: 도입 후 6개월 이내
사례 2. 제조업 — 비전 기반 표면 결함 탐지 (딥러닝)
자동차 부품 제조사에서 수작업 육안 검사로 인한 불량품 출고 문제가 지속 발생했습니다. 비젠소프트는 CNN 기반 딥러닝 비전 검사 시스템을 구축했습니다. 초기 학습 데이터 부족 문제는 데이터 증강(Data Augmentation) 기법으로 극복했습니다.
- 결과: 검사 정확도 99.2% 달성 (기존 육안 검사 대비 16%p 향상)
- 불량품 출고율 91% 감소, 검사 인력 비용 연간 3억 원 절감
- 프로젝트 기간: 약 6개월 / 시스템 24시간 무중단 가동
사례 3. 금융 서비스 — 이상 거래 탐지 모델 (머신러닝)
핀테크 스타트업에서 사기 거래 탐지 정확도를 높이면서 동시에 금융 감독 기관의 설명 가능성 요건을 충족해야 했습니다. 비젠소프트는 Gradient Boosting + SHAP(설명 가능한 AI 라이브러리) 조합으로 고성능 + 설명 가능한 이상 탐지 시스템을 구축했습니다.
- 결과: 사기 탐지율 기존 대비 47% 향상, 오탐(False Positive) 비율 38% 감소
- 규제 요건 100% 충족 (의사결정 근거 자동 리포트 생성)
- 프로젝트 기간: 약 3개월
---
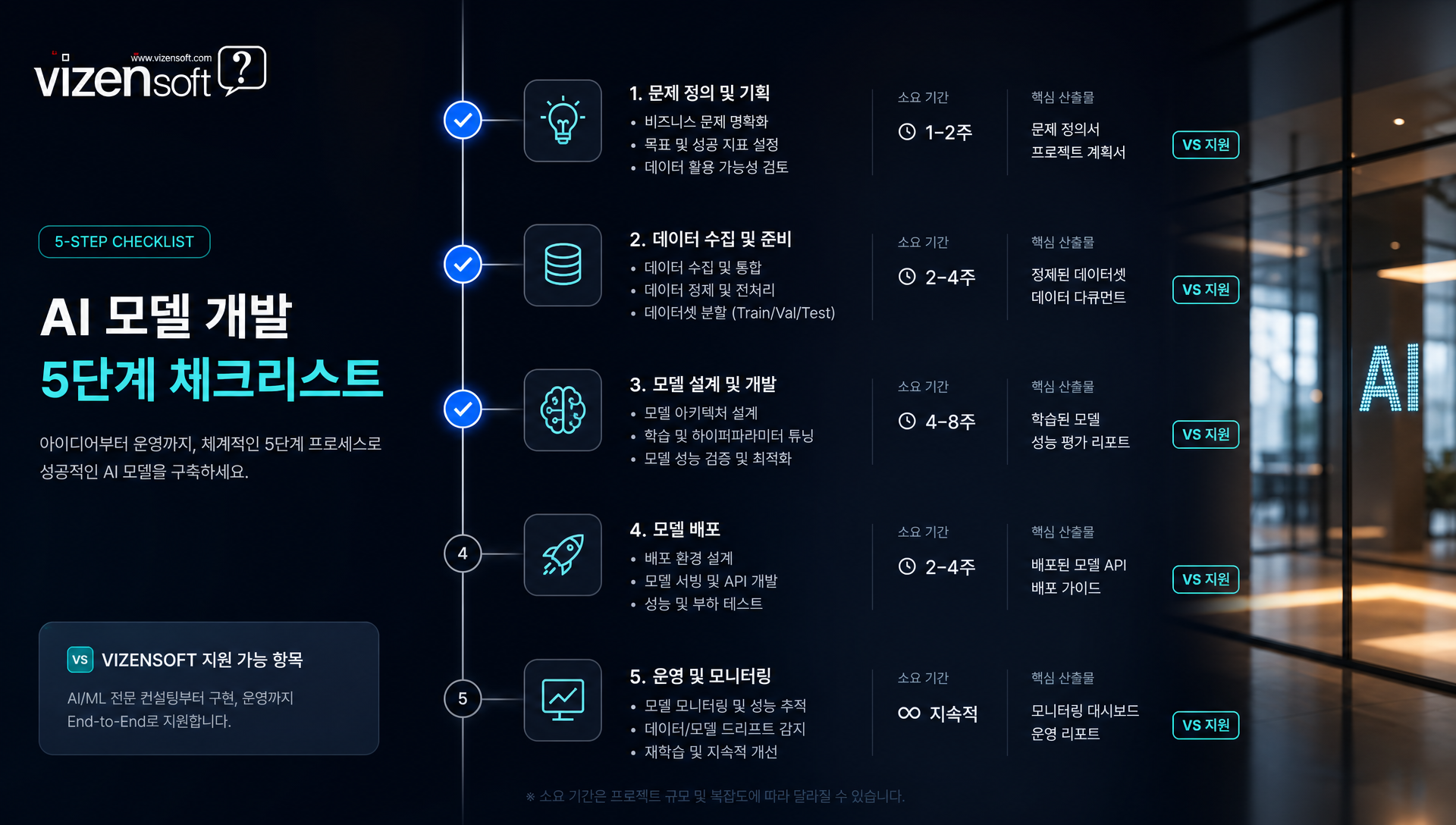
✅ AI 모델 개발 시작 전 체크리스트 — 실패 없는 프로젝트를 위한 단계별 가이드
AI 모델 개발 프로젝트를 시작하기 전에 반드시 점검해야 할 단계별 체크리스트를 제공합니다. 이 가이드를 따르면 방향성 혼란과 예산 낭비를 크게 줄일 수 있습니다.
1단계: 비즈니스 문제 정의 (가장 중요! 📌)
- ☑ 해결하고자 하는 비즈니스 문제가 명확히 정의되어 있는가?
- ☑ AI 도입으로 달성하고자 하는 정량적 KPI가 설정되어 있는가?
- ☑ AI가 아닌 다른 방법(규칙 기반, 통계 분석)으로는 해결이 불가능한가?
2단계: 데이터 현황 진단
- ☑ 학습에 사용할 수 있는 과거 데이터가 충분히 확보되어 있는가?
- ☑ 데이터 품질(결측치, 이상치, 레이블 정확도)이 일정 수준 이상인가?
- ☑ 데이터의 형태는 정형인가, 비정형(이미지/텍스트/음성)인가?
3단계: 방법론 선택 (본 글의 핵심!)
- ☑ 5가지 황금 기준(데이터 규모/문제 성격/설명 요건/예산/기간)을 모두 검토했는가?
- ☑ 머신러닝, 딥러닝, 하이브리드 중 최적 방법론을 선택했는가?
- ☑ 오버피팅, 데이터 불균형 등 예상 문제에 대한 대응 방안이 있는가?
4단계: 인프라 및 팀 구성
- ☑ 필요한 연산 자원(CPU/GPU, 클라우드)이 확보되어 있는가?
- ☑ 데이터 과학자, 엔지니어, 도메인 전문가가 포함된 팀이 구성되어 있는가?
5단계: MVP 구축 및 검증
- ☑ 전체 시스템 구축 전에 소규모 PoC(개념 증명)를 먼저 진행했는가?
- ☑ 성능 평가 지표(Accuracy, Precision, Recall, AUC 등)가 사전에 합의되어 있는가?
- ☑ 운영 환경 배포(MLOps) 계획이 개발 초기부터 수립되어 있는가?
| 단계 | 소요 기간 | 핵심 산출물 | 비젠소프트 지원 |
|---|---|---|---|
| 비즈니스 문제 정의 | 1~2주 | AI 과제 정의서 | ✅ 무료 컨설팅 |
| 데이터 현황 진단 | 2~4주 | 데이터 품질 리포트 | ✅ 데이터 분석 지원 |
| 방법론 선택 | 1~2주 | AI 아키텍처 설계서 | ✅ 전문가 리뷰 |
| MVP 구축·검증 | 4~8주 | PoC 결과 리포트 | ✅ 전담 개발팀 |
| 운영 시스템 구축 | 8~16주 | 완성 AI 시스템 | ✅ 배포·유지보수 |
---
💰 AI 모델 도입 효과 & ROI — 구체적인 숫자로 보는 비즈니스 가치
AI 모델 개발·도입의 비즈니스 가치를 수치로 살펴보겠습니다. 글로벌 리서치 기관과 비젠소프트 프로젝트 데이터를 종합하면, 올바른 방법론을 선택하고 체계적으로 구축된 AI 시스템은 평균 12~18개월 내에 투자 비용을 회수하고, 이후 지속적인 가치를 창출합니다.
① 비용 절감 효과
- 제조 품질 검사 자동화 → 검사 인건비 연평균 40~60% 절감
- 수요 예측 고도화 → 재고 비용 15~25% 절감
- 금융 이상 탐지 → 사기 손실 30~50% 감소
② 매출 증대 효과
- 고객 이탈 예측 + CRM 연계 → 이탈 고객 감소로 매출 8~15% 증가
- 개인화 추천 모델 → 평균 구매 단가 12~20% 향상
③ 운영 효율화 효과
- 문서 처리 자동화 (딥러닝 OCR + NLP) → 처리 시간 70~85% 단축
- 예측 정비 시스템 → 설비 다운타임 20~35% 감소
머신러닝 vs 딥러닝의 ROI를 비교할 때 중요한 점은, 단순히 모델 성능만 볼 것이 아니라 개발 비용, 운영 비용, 유지보수 비용까지 포함한 TCO(총 소유 비용) 대비 가치를 측정해야 한다는 것입니다. 비젠소프트는 고객사에 AI 프로젝트 ROI 시뮬레이션 서비스를 제공하고 있습니다. 도입을 고려하신다면 아래 서명 블록을 통해 문의해보세요.

---
❓ 자주 묻는 질문 (FAQ)
Q1. 우리 회사 데이터가 많지 않아도 AI 모델 개발이 가능한가요?
A. 가능합니다. 데이터가 부족한 경우에는 여러 전략을 활용할 수 있습니다. 정형 데이터라면 머신러닝 알고리즘이 수천 건의 데이터만으로도 충분한 성능을 발휘합니다. 이미지나 텍스트 데이터가 부족하다면 전이 학습(Transfer Learning) 을 통해 이미 수백만 건의 데이터로 사전 학습된 모델을 활용하고, 소량의 내부 데이터로 파인튜닝하는 방식으로 고성능 모델 구현이 가능합니다. 또한 데이터 증강(Augmentation) 기법으로 기존 데이터를 확장할 수 있습니다. 비젠소프트는 데이터 현황에 맞는 최적화 전략을 제안합니다.
Q2. 머신러닝과 딥러닝 중 어떤 것이 더 비싼가요?
A. 일반적으로 딥러닝 프로젝트가 더 많은 비용이 발생합니다. 딥러닝은 고성능 GPU 인프라 비용, 더 긴 개발 기간, 더 많은 데이터 수집·가공 비용이 필요하기 때문입니다. 반면 머신러닝은 일반 CPU 서버에서도 학습이 가능하고, 개발 기간이 짧아 인건비도 절약됩니다. 그러나 딥러닝이 필요한 문제(이미지, 텍스트 등)에서는 딥러닝 투자가 결국 더 높은 ROI를 창출합니다. 문제의 성격에 맞는 방법론 선택이 비용 효율의 핵심입니다.
Q3. AI 모델을 한 번 구축하면 계속 잘 작동하나요?
A. 안타깝게도 그렇지 않습니다. AI 모델은 데이터 드리프트(Data Drift) 문제로 시간이 지남에 따라 성능이 저하됩니다. 비즈니스 환경이 변하면 데이터 패턴도 변하기 때문입니다. 이 때문에 MLOps(모델 운영 체계) 를 통한 지속적인 모델 모니터링, 재학습(Retraining), 성능 관리가 필수입니다. 비젠소프트는 모델 구축에서 끝나는 것이 아니라 지속적인 모델 유지보수 및 MLOps 운영 서비스를 함께 제공합니다.
Q4. 비젠소프트에 AI 모델 개발을 맡기면 어떤 과정으로 진행되나요?
A. 크게 5단계로 진행됩니다.
Step 1. 무료 사전 컨설팅 — 비즈니스 문제 진단 및 AI 적용 가능성 검토
Step 2. 데이터 현황 분석 및 방법론 제안 — 최적 알고리즘 및 아키텍처 설계
Step 3. PoC(개념 증명) 구축 — 소규모 시범 모델 개발 및 성능 검증
Step 4. 본 시스템 개발 및 통합 — 운영 환경에 맞는 전체 시스템 구축
Step 5. 배포 및 유지보수 — MLOps 체계 구축 및 지속적 모델 관리
Q5. 클라우드 AI 서비스(AWS, Azure, Google Cloud)와 비젠소프트 맞춤 개발은 어떻게 다른가요?
A. 클라우드 AI 서비스는 범용 목적으로 설계된 표준화된 솔루션이라 우리 회사만의 고유한 데이터 특성과 비즈니스 로직을 반영하기 어렵습니다. 반면 비젠소프트의 맞춤형 AI 모델 개발은 고객사 데이터와 도메인 특성에 완전히 최적화된 모델을 구축하므로, 표준 솔루션 대비 일반적으로 20~40% 높은 예측 정확도를 달성합니다. 초기 비용은 다소 높을 수 있으나, 중장기적 ROI는 맞춤형 개발이 훨씬 우수한 경우가 많습니다.
---
🎯 마무리 — 목적에 맞는 AI를 선택하는 것이 가장 강력한 AI 전략입니다
지금까지 머신러닝과 딥러닝의 핵심 차이, 비즈니스 목적에 따른 최적 방법론 선택 기준, 실전 성공 사례와 ROI까지 심층적으로 살펴봤습니다. 핵심 메시지를 한 번 더 정리하겠습니다.
첫째, AI 방법론에는 절대적인 우열이 없습니다. 딥러닝이 무조건 더 좋은 것도, 머신러닝이 구식인 것도 아닙니다. 비즈니스 문제와 데이터 현황에 가장 잘 맞는 방법론이 최선입니다.
둘째, 정형 데이터 + 소규모 데이터 + 빠른 개발 + 설명 가능성 요건이 있다면 머신러닝이 최적입니다.
셋째, 비정형 데이터(이미지/텍스트/음성) + 복잡한 패턴 + 충분한 데이터와 예산이 있다면 딥러닝을 선택하세요.
넷째, 현실 비즈니스 문제의 많은 부분은 머신러닝 + 딥러닝의 하이브리드 접근법으로 가장 효율적으로 해결됩니다.
비젠소프트는 머신러닝과 딥러닝 모두에 전문성을 갖춘 AI 모델 개발 전문 기업으로, 고객사의 데이터와 목적에 최적화된 AI 솔루션을 설계하고 구축합니다. 'AI를 도입하고 싶은데 어디서부터 시작해야 할지 모르겠다'는 막막함을 느끼고 계신다면, 지금 바로 아래 서명 블록을 통해 비젠소프트에 문의해 보세요. 무료 사전 컨설팅을 통해 여러분의 비즈니스에 맞는 AI 전략을 함께 설계해 드리겠습니다. 🚀
🏢 비젠소프트 (VIZENSOFT) | AI 모델 개발 · 머신러닝 · 딥러닝 전문
📧 | 🌐 www.vizensoft.com | 📞
데이터에서 비즈니스 가치를 발굴하는 AI 파트너, 비젠소프트와 함께하세요 🚀
🔗 https://www.vizensoft.com






