-
통찰력 있는 사람들이 함께하는 젊고 열정적인 IT 기업, 비젠소프트.
A young and passionate technology company,
brought together by people with keen insight—this is Vizensoft. -

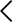 Back
Back소형 언어모델(SLM) 완벽 비교, Phi·Gemma·EXAONE 중 내 서비스엔 뭐가 맞을까?
소형 언어모델(SLM) 완벽 비교, Phi·Gemma·EXAONE 중 내 서비스엔 뭐가 맞 - 이 말, 정말 많이 들립니다. 실제로 AI 도입을 검토하는 중소기업·스타트업 담당자들
 완벽 비교, Phi·Gemma·EXAONE 중 내 서비스엔 뭐가 맞을까?")
# 소형 언어모델(SLM) 완벽 비교: Phi·Gemma·EXAONE 중 내 서비스엔 뭐가 맞을까?
GPT-4 비용의 1/100로 같은 품질을 낼 수 있다면, 당신은 아직도 대형 모델만 고집하시겠습니까?
---
🤖 "AI 도입하고 싶은데 비용이 너무 부담스럽습니다"
이 말, 정말 많이 들립니다. 실제로 AI 도입을 검토하는 중소기업·스타트업 담당자들과 이야기를 나눠보면, "GPT-4 API를 프로덕션에 붙였더니 월 수백만 원이 나왔다" 는 경험담을 공통적으로 토로합니다. 하루 수천 건의 문서 분류, 고객 응대 요약, 내부 검색 쿼리를 대형 LLM에 던질 때마다 토큰 비용이 눈덩이처럼 불어나는 현실. 더 심각한 문제는 응답 지연입니다. GPT-4 수준의 모델은 서버 왕복 레이턴시가 발생하기 때문에, 실시간 응답이 필요한 서비스에선 사용자 경험이 급격히 떨어집니다.
그렇다고 AI를 포기할 수는 없죠. 이미 경쟁사들은 AI로 CS 인력을 줄이고, 문서 처리 속도를 5배 높이며, 24시간 자동 응답 시스템을 운영하고 있습니다. 이 격차를 방치하면 시장에서 도태될 수밖에 없습니다.
여기서 등장한 해법이 바로 소형 언어모델(SLM, Small Language Model) 입니다. 2024~2025년을 거치며 Microsoft, Google, Meta, LG AI Research 등 빅테크와 국내 AI 기업들이 잇달아 출시한 SLM들은 GPT-4 대비 추론 비용을 최대 1/100 수준으로 낮추면서도, 분류·요약·번역·간단 응답 등 실무 작업에서는 대형 모델과 거의 동등한 성능을 보여주고 있습니다. 온디바이스 AI 구현까지 가능해지면서 클라우드 없이 스마트폰이나 엣지 디바이스에서 직접 AI를 돌리는 시대도 현실이 됐습니다.
문제는 Phi, Gemma, Llama, EXAONE, Qwen, Solar Mini 등 수십 가지 SLM 중에서 어떤 모델이 내 서비스에 맞는지 를 판단하는 기준이 없다는 것입니다. 이 글은 그 기준을 명확히 제시하기 위해 작성됐습니다. 벤치마크 수치, 비용 비교, 적합 작업 영역, 실전 도입 사례까지 한 번에 정리해 드리겠습니다.

---
📚 SLM이란 무엇인가? 대형 LLM과 어떻게 다른가
소형 언어모델(SLM) 은 통상 파라미터 수 기준으로 1B(10억)~20B(200억) 규모의 언어 모델을 가리킵니다. GPT-4가 추정 1조 파라미터 이상, Claude 3 Opus가 수천억 파라미터 규모인 것과 비교하면 물리적 크기 자체가 압도적으로 작습니다. 그런데 '작다 = 성능이 낮다'는 공식이 2023년부터 급격히 무너지기 시작했습니다.
그 이유는 크게 세 가지입니다.
첫째, 학습 데이터 고품질화입니다. Microsoft의 Phi 시리즈는 "교과서 품질(Textbook Quality)" 데이터로 소량 고밀도 학습을 수행해 동급 최고 수준의 추론 능력을 달성했습니다.
둘째, 증류(Distillation) 기술 발전입니다. 대형 모델의 지식을 소형 모델로 전이시키는 Knowledge Distillation 기법이 고도화되면서, 작은 모델도 대형 모델의 패턴 인식 능력을 흡수할 수 있게 됐습니다.
셋째, 아키텍처 최적화입니다. Grouped Query Attention, Sliding Window Attention 등 최신 어텐션 기법들이 추론 효율을 극대화하고 있습니다.
결과적으로 오늘날 최고 수준의 SLM들은 2022년 기준 GPT-3.5급 성능을 1/50 이하의 비용으로 제공합니다. 분류, 요약, 번역, 간단한 Q&A처럼 "폭넓은 일반 지식"보다 "빠르고 정확한 특정 작업"이 중요한 유즈케이스에서는 SLM이 GPT-4를 실질적으로 능가하는 경우도 있습니다. 특히 온디바이스 AI 구현 관점에서는 SLM이 사실상 유일한 선택지입니다. 스마트폰·노트북·임베디드 기기에서 인터넷 연결 없이 AI를 구동하려면 모델이 충분히 작아야 하기 때문입니다.

---
🔬 주요 SLM 라인업 완전 분석: 모델별 성능과 특징
2025년 현재 실무에서 주목받는 SLM은 6개 계열로 정리됩니다. 각 모델의 기술적 특성과 벤치마크 성능을 면밀히 살펴보겠습니다.
Phi-4 / Phi-3 (Microsoft)
Microsoft의 Phi 시리즈는 "작지만 강하다"는 SLM 철학의 교과서입니다. 2024년 말 출시된 Phi-4(14B) 는 MMLU 벤치마크에서 84.8점을 기록했으며, 이는 GPT-3.5(70B급)를 넘어서는 수치입니다. 코딩 특화 벤치마크인 HumanEval에서도 82.6점으로 동급 모델 중 최상위권에 위치합니다. Phi-3-mini(3.8B)는 스마트폰 온디바이스 구동이 가능한 최소 사이즈로, Qualcomm Snapdragon 탑재 안드로이드 폰에서 실시간 추론이 검증됐습니다. Microsoft는 Phi 시리즈를 Azure AI Studio에 완전 통합하여 엔터프라이즈 도입 장벽을 크게 낮췄습니다. 수학적 추론, 코드 생성, 논리적 분석 작업에서 특히 두각을 나타내며, 라이선스도 MIT로 상업적 활용이 자유롭습니다.
Gemma 2 (Google)
Google의 Gemma 2는 2B / 9B / 27B 세 가지 사이즈로 출시되어 다양한 하드웨어 환경을 커버하는 포트폴리오 전략을 취합니다. Gemma 2-9B는 MMLU에서 71.3점을 기록하며 같은 크기대 최고 수준이며, Gemma 2-27B는 75.2점으로 Llama 2-70B와 유사한 성능을 1/3 크기로 달성했습니다. Google TPU 최적화를 통해 추론 속도가 경쟁사 대비 20~30% 빠르며, Hugging Face와의 완벽한 통합으로 파인튜닝 생태계가 매우 풍부합니다. 다만 상업적 이용 시 월간 활성 사용자 수에 따른 조건이 있어 라이선스 확인이 필수입니다. 멀티모달 확장(이미지 이해)을 지원하는 PaliGemma 파생 모델도 있어 비전+텍스트 복합 유즈케이스에도 대응 가능합니다.
Llama 3.2 (Meta)
Meta의 Llama 3.2는 1B / 3B 초소형 모델로 온디바이스 AI 최적화에 초점을 맞춥니다. 1B 모델은 RAM 2GB 이하의 환경에서 구동 가능하며, iOS·Android 공식 지원으로 모바일 앱 내장 AI의 현실적 선택지가 됐습니다. MMLU 기준 1B 모델은 약 49.3점, 3B 모델은 58.0점으로 절대 성능보다 엣지 환경에서의 응답 속도(3B 기준 스마트폰에서 30~50 tokens/sec)가 강점입니다. Meta의 커뮤니티 생태계 덕분에 Llama 계열 파인튜닝 데이터셋과 레시피가 가장 풍부하며, Llama.cpp를 통한 CPU 추론도 안정적입니다.
EXAONE 2.4B (LG AI Research)
국내 기업 관점에서 가장 주목해야 할 모델입니다. LG AI Research가 개발한 EXAONE 2.4B는 한국어 특화 SLM으로, KMMLU(한국어 MMLU) 벤치마크에서 동급 최고 성능을 기록하고 있습니다. KMMLU 점수는 공개 기준 53.7점으로, 같은 파라미터 크기의 해외 모델들이 한국어 처리에서 30~40점대에 머무는 것과 대조적입니다. 법률, 의학, 금융 등 전문 한국어 도메인 데이터로 학습되어 한국어 문서 분류·요약·번역 작업에서 압도적 우위를 보입니다. 온프레미스 배포가 가능하고 기업 라이선스 정책이 유연하여 금융·의료·공공 분야의 데이터 보안 요건을 충족하기 유리합니다.
Qwen 2.5 (Alibaba) & Solar Mini (Upstage)
Alibaba의 Qwen 2.5는 0.5B부터 72B까지 다양한 크기를 제공하며 중국어·영어·한국어를 포함한 29개 언어 다국어 처리에 강점이 있습니다. 글로벌 서비스나 다국어 고객 응대가 필요한 서비스라면 매우 매력적인 선택지입니다. Upstage의 Solar Mini는 한국어 특화 모델로 KMMLU에서 우수한 성능을 보이며, 국내 클라우드 API 형태로 제공되어 접근성이 높습니다.
---
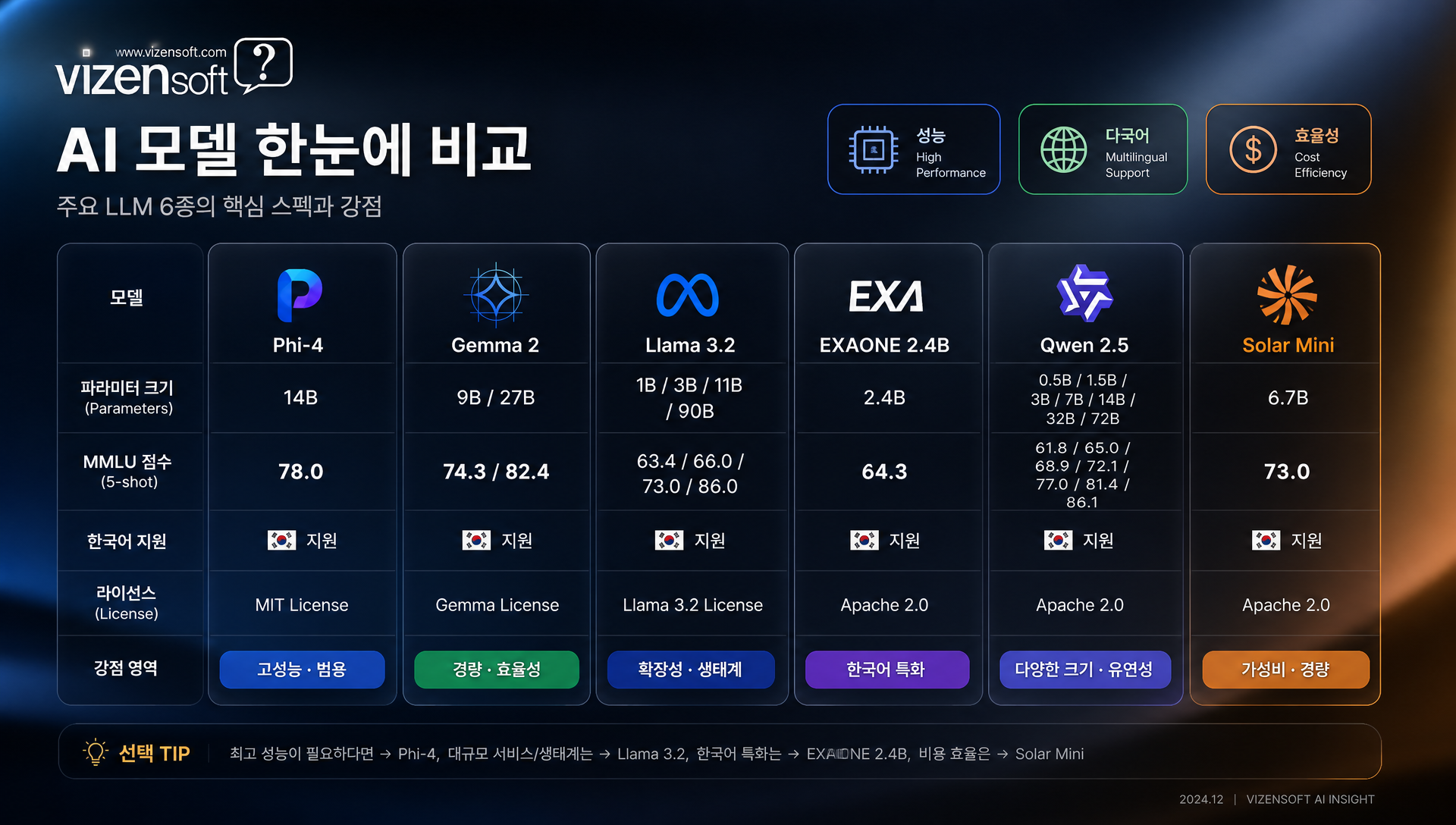
💰 비용·속도·메모리: 숫자로 보는 SLM vs 대형 LLM
이론은 충분합니다. 이제 가장 중요한 실제 운영 비용과 성능 수치를 살펴보겠습니다. 아래 데이터는 공개된 API 가격과 벤치마크 결과를 기반으로 정리한 것입니다.
추론 비용 비교 (입력 1M 토큰 기준, 2025년 상반기 기준)
| 모델 | 파라미터 | 입력 비용($/1M tokens) | 출력 비용($/1M tokens) | GPT-4o 대비 |
|---|---|---|---|---|
| GPT-4o | ~수천억 | $5.00 | $15.00 | 기준(1x) |
| Claude 3.5 Sonnet | ~수천억 | $3.00 | $15.00 | ~0.6x |
| Gemma 2-9B (Self-hosted) | 9B | $0.03~0.08 | $0.03~0.08 | ~1/100x |
| Phi-4 (Azure) | 14B | $0.05 | $0.10 | ~1/80x |
| Llama 3.2-3B (Self-hosted) | 3B | $0.01~0.03 | $0.01~0.03 | ~1/300x |
| EXAONE 2.4B (Self-hosted) | 2.4B | $0.01~0.02 | $0.01~0.02 | ~1/400x |
※ Self-hosted 기준은 GPU 서버 임대비(A10G 기준) 포함 추정치이며 실제 환경에 따라 달라질 수 있습니다.
월 100만 건의 고객 문의 요약 작업을 가정하면, GPT-4o 기준 월 약 700~1,500만 원의 API 비용이 발생하지만, Llama 3.2-3B나 EXAONE 2.4B를 자체 서버에서 운영하면 월 30~80만 원 수준으로 낮출 수 있습니다. 연간 기준으로 1억 원 이상의 비용 차이가 발생하는 셈입니다.
응답 속도 비교 (A100 GPU 기준, tokens/sec)
| 모델 | 크기 | 속도(tokens/sec) | 평균 응답 지연 |
|---|---|---|---|
| GPT-4o (API) | 대형 | 60~80 | 1.5~3초 (네트워크 포함) |
| Gemma 2-9B | 9B | 120~180 | 0.3~0.8초 |
| Phi-4 | 14B | 80~120 | 0.5~1.0초 |
| Llama 3.2-3B | 3B | 300~450 | 0.1~0.3초 |
| EXAONE 2.4B | 2.4B | 350~500 | 0.1~0.2초 |
메모리 요구량 (FP16 기준)
| 모델 | VRAM 요구량 | 가능한 GPU |
|---|---|---|
| Llama 3.2-1B | ~2GB | RTX 3060 이상 |
| EXAONE 2.4B | ~5GB | RTX 3070 이상 |
| Gemma 2-2B | ~4GB | RTX 3060 이상 |
| Phi-4 (14B) | ~28GB | A10G / RTX 4090 |
| Gemma 2-27B | ~54GB | A100 80GB |
이 데이터가 말하는 것은 명확합니다. 소형 모델일수록 응답 속도가 3~6배 빠르고, 비용은 80~400배 저렴하며, 일반 소비자용 GPU로도 운영 가능합니다. 물론 성능 트레이드오프가 있지만, 작업 유형에 따라 그 트레이드오프가 사실상 의미 없는 경우도 많습니다.
---
🎯 어떤 작업에 SLM이 최적인가? 적합 영역 완전 가이드
SLM 도입의 성패는 "올바른 작업에 올바른 모델을 배치하느냐" 에 달려 있습니다. SLM이 빛나는 작업 영역과, 반드시 대형 모델이 필요한 영역을 명확히 구분해야 합니다.
✅ SLM이 충분히 잘 처리하는 작업
① 텍스트 분류 (Classification)
고객 문의를 카테고리(환불/배송/기술지원 등)로 분류하거나, 감성 분석(긍정/부정/중립)을 수행하는 작업은 2~7B 수준의 SLM으로도 95% 이상의 정확도를 달성할 수 있습니다. 파인튜닝을 적용하면 GPT-4와 동등하거나 더 높은 도메인 정확도가 가능합니다.
② 문서 요약 (Summarization)
정형화된 패턴이 있는 문서(계약서 요약, 뉴스 요약, 회의록 정리)는 9~14B SLM으로 충분합니다. 특히 RAG(Retrieval-Augmented Generation) 파이프라인에서 검색된 청크를 요약하는 reranker 역할에 탁월합니다.
③ 번역 (Translation)
한국어↔영어 양방향 번역은 Qwen 2.5나 EXAONE 계열이 전문 번역 수준에 근접합니다. 특히 도메인 특화 용어가 많은 경우 파인튜닝된 SLM이 범용 대형 모델보다 오히려 더 정확할 수 있습니다.
④ FAQ 응답 / 챗봇 1차 응대
FAQ 데이터베이스 기반의 1차 응대는 SLM의 가장 전형적인 유즈케이스입니다. 응답 패턴이 어느 정도 정해져 있고 속도가 중요한 환경에서 SLM은 월등한 가성비를 발휘합니다.
⑤ RAG Retriever / Reranker
검색 결과를 관련도 순으로 재정렬하거나 간단한 질의에 컨텍스트를 매핑하는 작업은 소형 임베딩 모델과 SLM의 조합으로 구현할 수 있습니다. 비용 대비 효과가 가장 극적인 영역 중 하나입니다.
⑥ 코드 자동완성 / 간단한 코드 생성
Phi-4나 Qwen 2.5-Coder는 HumanEval 기준 80점 이상으로, IDE 내 코드 자동완성이나 반복 패턴 코드 생성에 충분한 성능을 발휘합니다.
⚠️ 대형 모델 Fallback이 필요한 작업
복잡한 다단계 추론, 창의적 장문 작성, 전문 법률·의학 자문, 다중 문서 교차 분석 등은 SLM의 한계가 명확히 드러나는 영역입니다. 이때는 "1차 SLM → 복잡 케이스만 대형 모델 Fallback" 하이브리드 아키텍처가 최선입니다. 실제로 이 구조를 적용하면 전체 쿼리의 70~80%를 SLM이 처리하고 나머지만 대형 모델로 넘겨 평균 비용을 60~75% 절감하면서도 전체 서비스 품질을 유지할 수 있습니다.

---
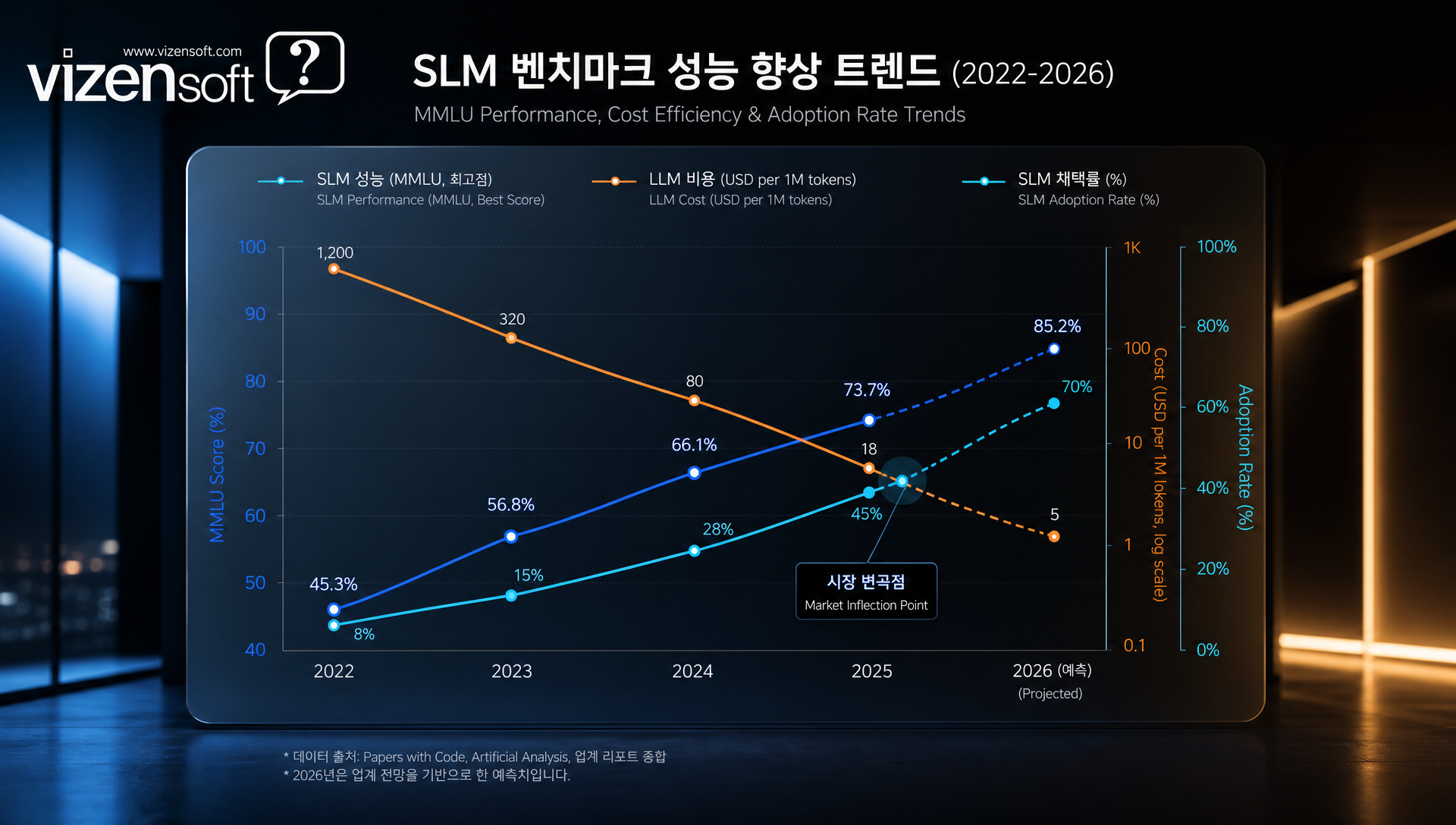
📊 벤치마크 심층 분석: MMLU·KMMLU·HumanEval로 성능 검증
벤치마크 수치는 모델 선택의 출발점이지만, 어떤 벤치마크를 어떻게 해석하느냐가 핵심입니다. 잘못된 벤치마크 기준으로 모델을 선택하면 실무 성능과 큰 괴리가 생길 수 있습니다.
주요 벤치마크 설명
MMLU (Massive Multitask Language Understanding) 는 57개 학문 분야 객관식 문제로 언어모델의 광범위한 지식과 추론 능력을 평가합니다. 범용 성능의 대표 지표이지만, 한국어 능력은 직접 반영되지 않습니다.
KMMLU (Korean MMLU) 는 한국어로 출제된 MMLU 형식의 벤치마크로, 한국어 서비스 개발자라면 반드시 확인해야 할 지표입니다. 동일 모델이라도 MMLU 대비 KMMLU 점수 차이가 크게 나타날 수 있습니다.
HumanEval 은 164개 Python 코딩 문제로 코드 생성 능력을 측정합니다. 개발 보조 도구나 코딩 어시스턴트 구현 시 주요 참고 지표입니다.
종합 벤치마크 비교표
| 모델 | 파라미터 | MMLU | KMMLU | HumanEval | 특화 강점 |
|---|---|---|---|---|---|
| GPT-4o | 대형 | 88.7 | 74.2 | 90.2 | 전방위 |
| Phi-4 | 14B | 84.8 | 58.1 | 82.6 | 수학·코딩 |
| Gemma 2-27B | 27B | 75.2 | 52.3 | 74.1 | 다국어 |
| Gemma 2-9B | 9B | 71.3 | 48.7 | 68.2 | 범용 중형 |
| EXAONE 2.4B | 2.4B | 53.7 | 53.7 | 42.1 | 한국어 |
| Llama 3.2-3B | 3B | 58.0 | 41.2 | 51.3 | 온디바이스 |
| Qwen 2.5-7B | 7B | 74.2 | 55.8 | 72.3 | 다국어 |
| Solar Mini | ~10B | 70.1 | 62.4 | 65.8 | 한국어 |
이 표에서 주목할 점은 EXAONE 2.4B의 KMMLU 점수가 파라미터 크기 대비 극도로 높다는 것입니다. 2.4B 모델이 KMMLU에서 53.7점을 기록하는 것은 한국어 특화 학습의 효과를 여실히 보여줍니다. 한국어 서비스를 운영한다면 파라미터 크기만 보고 해외 모델을 선택하는 것은 실수가 될 수 있습니다.
반면 Phi-4는 파라미터 대비 MMLU와 HumanEval 모두에서 압도적 효율을 보입니다. 영어 기반 코딩·수학 서비스라면 Phi-4가 단연 최선의 선택입니다.
---
🔍 SLM별 추천 유즈케이스 비교
지금까지의 데이터를 바탕으로 서비스 유형별로 어떤 SLM을 선택해야 하는지 명확한 가이드를 제시합니다.
| 서비스 유형 | 추천 1순위 | 추천 2순위 | 이유 |
|---|---|---|---|
| 한국어 CS 챗봇 | EXAONE 2.4B | Solar Mini | 한국어 KMMLU 최상위, 빠른 응답 |
| 코드 자동완성 | Phi-4 (14B) | Qwen 2.5-Coder | HumanEval 82.6점, 수학 추론 우수 |
| 모바일 온디바이스 AI | Llama 3.2-1B/3B | Phi-3-mini | 초소형, 모바일 SDK 공식 지원 |
| 다국어 글로벌 서비스 | Qwen 2.5-7B | Gemma 2-9B | 29개 언어, 균형 잡힌 다국어 성능 |
| RAG 파이프라인 | Gemma 2-9B | Phi-4 | 빠른 추론, 컨텍스트 이해 우수 |
| 비용 최우선 경량 배포 | Llama 3.2-3B | EXAONE 2.4B | 최저 비용, 충분한 범용 성능 |
| 엔터프라이즈 보안 환경 | EXAONE 2.4B | Gemma 2-9B | 온프레미스 배포, 한국 기업 친화적 |

---
🏭 실전 활용 사례: 기업들은 어떻게 SLM을 도입했나
실제 도입 사례를 통해 SLM의 비즈니스 가치를 구체적으로 확인해 보겠습니다.
사례 1: 금융권 문서 처리 자동화 (EXAONE 2.4B 활용)
국내 한 중형 금융사는 하루 평균 5만 건의 고객 민원 서류를 담당자가 수동으로 분류하고 요약하는 작업에 총 32명의 인력을 투입하고 있었습니다. 대형 LLM API를 검토했으나 월 추정 비용 2,200만 원과 데이터 보안 우려로 도입을 주저했습니다. EXAONE 2.4B를 자사 온프레미스 서버에 배포하고 도메인 파인튜닝을 적용한 결과, 분류 정확도 94.2%, 요약 품질 만족도 91% 를 달성했습니다. 운영 비용은 서버 포함 월 85만 원으로 감소했으며, 담당 인력 32명 중 24명을 고부가가치 업무로 재배치할 수 있었습니다. 연간 절감 비용만 환산하면 약 8억 5천만 원 수준으로 추정됩니다.
사례 2: 스타트업 모바일 앱 온디바이스 AI (Llama 3.2-3B 활용)
영어 학습 앱을 운영하는 한 스타트업은 사용자의 영작문 첨삭 서비스를 GPT-4 API로 운영하다가 MAU 증가와 함께 API 비용이 월 1,800만 원까지 치솟는 상황에 처했습니다. Llama 3.2-3B를 iOS/Android에 온디바이스로 내장하고 간단한 문법 오류 및 표현 개선 제안은 기기 내에서 처리하도록 아키텍처를 재설계했습니다. 복잡한 고급 첨삭만 서버 측 중형 모델로 처리하는 하이브리드 방식을 적용한 결과, 전체 쿼리의 78%가 온디바이스에서 처리되어 API 비용이 월 320만 원으로 82% 감소했습니다. 오프라인 환경에서도 기본 기능 제공이 가능해져 앱 리뷰 평점이 4.1점에서 4.6점으로 상승했습니다.
사례 3: 이커머스 다국어 상품 설명 자동화 (Qwen 2.5 활용)
글로벌 이커머스 플랫폼 운영사가 한국어·영어·일본어·중국어 4개 언어로 상품 설명을 자동 생성·번역하는 시스템을 구축했습니다. Qwen 2.5-7B를 도입하여 일 3만 건 상품 설명 생성 작업을 자동화했으며, 번역 품질 점수(BLEU) 기준 기존 전문 번역 서비스 대비 93% 수준을 달성하면서 비용은 1/8 수준으로 절감됐습니다. 무엇보다 신규 상품 등록부터 4개국어 설명 완성까지 소요 시간이 3일에서 2시간으로 단축된 것이 가장 큰 비즈니스 효과로 평가됩니다.

---
✅ SLM 도입 체크리스트: 단계별 실행 가이드
SLM 도입을 결정했다면 아래 단계를 순서대로 점검하세요.
Step 1. 유즈케이스 명확화
먼저 어떤 작업을 자동화할 것인지 정의합니다.
- 작업 유형은 분류·요약·번역·생성 중 어디에 해당하는가?
- 하루 처리 건수와 평균 입력 길이는 얼마인가?
- 응답 지연 허용 범위는 몇 초인가?
- 데이터가 외부 클라우드에 전송 가능한가, 아니면 온프레미스/온디바이스가 필요한가?
Step 2. 모델 후보 선정 (2~3개)
다음으로 유즈케이스 매트릭스를 기반으로 후보 모델을 2~3개로 압축합니다.
- 한국어 중심 서비스라면 EXAONE·Solar Mini 반드시 포함
- 코딩 관련 서비스라면 Phi-4·Qwen 2.5-Coder 포함
- 온디바이스 요구 시 Llama 3.2-1B/3B·Phi-3-mini 포함
Step 3. 소규모 PoC (Proof of Concept)
그리고 나서 실제 업무 데이터 1,000~5,000건으로 각 후보 모델을 테스트합니다.
- Hugging Face의 무료 inference endpoint 활용 가능
- 자체 평가 기준(정확도·속도·비용)으로 스코어카드 작성
Step 4. 파인튜닝 여부 결정
기본 모델(Base) 성능이 목표치의 80% 이상이면 파인튜닝 없이 프롬프트 엔지니어링으로 충분할 수 있습니다.
- 80% 미만이면 LoRA/QLoRA 파인튜닝 적용 검토
- 파인튜닝 데이터는 최소 1,000건 이상의 고품질 레이블 데이터 필요
Step 5. 인프라 설계
마지막으로 배포 환경을 결정합니다.
- 클라우드 GPU 인스턴스(비용 유연)
- 온프레미스 GPU 서버(보안·장기 비용 절감)
- 온디바이스 SDK 내장(모바일 앱)
- 하이브리드(SLM 1차 처리 + 대형 모델 Fallback)
| 구분 | 클라우드 배포 | 온프레미스 배포 | 온디바이스 |
|---|---|---|---|
| 초기 투자 | 낮음(월 과금) | 높음(서버 구매) | 낮음 |
| 월 운영 비용 | 중간 | 낮음(전기세 수준) | 거의 없음 |
| 보안 수준 | 중간 | 높음 | 최고 |
| 확장성 | 매우 높음 | 낮음 | 기기 제한 |
| 권장 규모 | 스타트업·중소기업 | 대기업·금융·의료 | 모바일 앱 |

---
📈 도입 효과 & ROI: 투자 대비 기대 수익
SLM 도입의 ROI는 크게 세 가지 축에서 발생합니다.
① 직접 비용 절감: 대형 LLM API 비용 대비 70~95% 절감이 일반적입니다. 월 500만 원 API 비용을 지출하던 서비스라면 SLM 전환 후 연간 4,200만~5,700만 원 절감이 가능합니다.
② 인건비 절감 및 생산성 향상: 문서 처리·분류·번역 자동화로 반복 작업 인력을 창의적·고부가가치 업무로 재배치할 수 있습니다. 중소기업 기준 2~5명의 업무를 자동화하면 연간 인건비 1억~2억 원 절감 효과가 발생합니다.
③ 서비스 품질·속도 향상에 따른 매출 기여: 응답 속도 3~6배 향상, 24시간 무중단 운영, 오프라인 지원(온디바이스)은 서비스 전환율과 사용자 만족도를 높여 간접적인 매출 성장에 기여합니다.
일반적으로 SLM 도입 프로젝트는 투자 회수 기간(Break-even) 3~6개월 이내, 1년 ROI 200~500% 수준이 보고되고 있습니다.

---
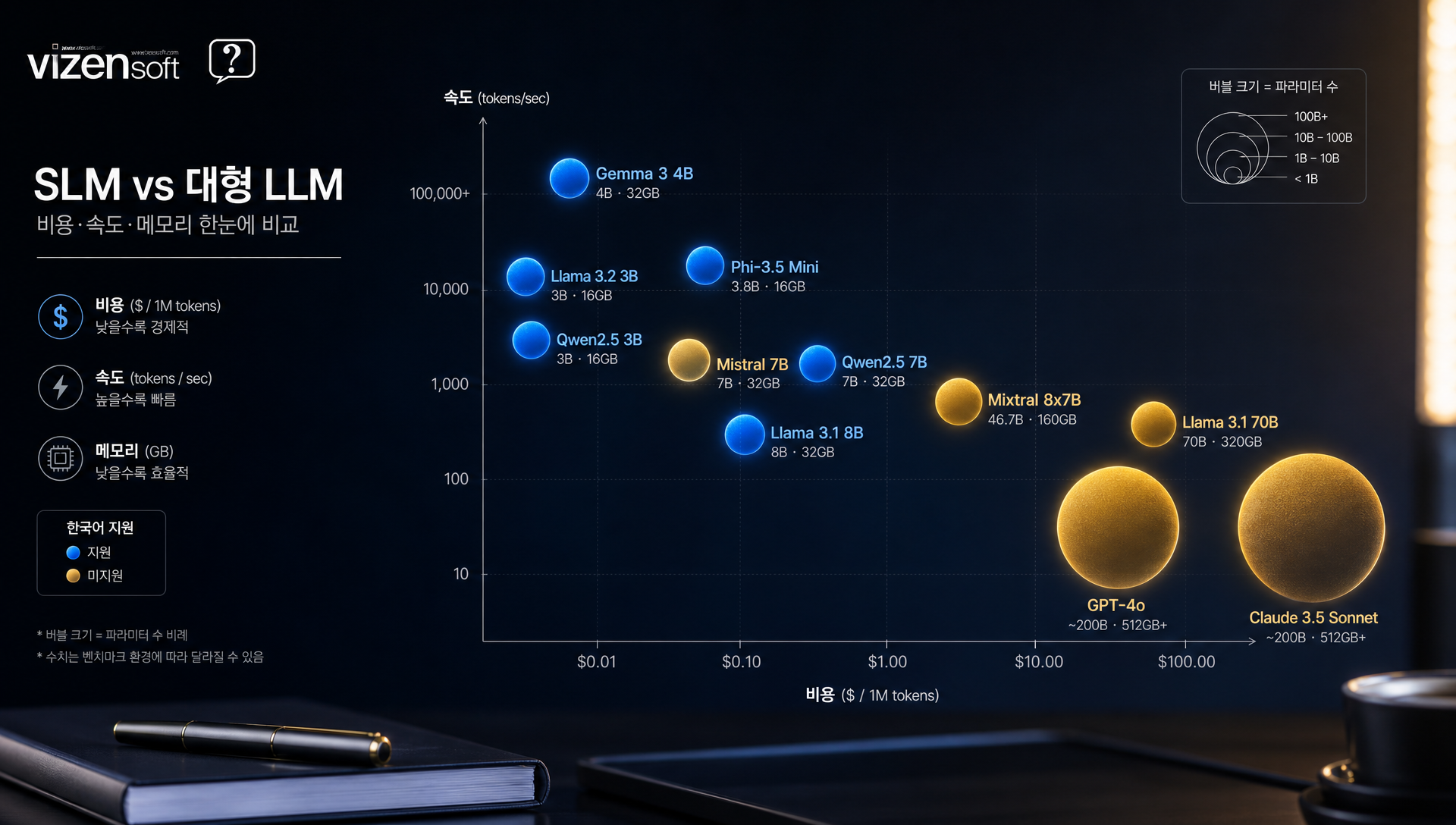
🌐 2026년 SLM 트렌드 전망: 온디바이스 AI 시대의 본격화
SLM 시장은 2024년 기점으로 폭발적 성장 궤도에 진입했습니다. IDC 분석에 따르면 온디바이스 AI 시장은 2023년 약 4조 원 규모에서 2028년까지 연평균 47% 성장, 약 50조 원 규모에 달할 것으로 전망됩니다.
2026년을 향한 핵심 트렌드는 다음과 같습니다.
① 스마트폰 네이티브 AI의 대중화: Qualcomm Snapdragon 8 Gen 4, Apple M4 칩 등 AI 전용 NPU(Neural Processing Unit)의 성능이 비약적으로 향상되면서 7~14B 수준의 SLM도 스마트폰에서 실시간 구동이 가능해질 전망입니다. Llama 3.2와 Phi-3-mini가 이미 이 방향을 개척하고 있습니다.
② 멀티모달 SLM의 부상: 텍스트만 처리하던 SLM이 이미지·음성·비디오를 함께 이해하는 멀티모달로 진화하고 있습니다. Gemma 3, Phi-4-Vision 등이 이 흐름을 주도하며, 2026년에는 멀티모달 SLM이 표준이 될 것으로 보입니다.
③ 한국어 SLM 생태계 성숙: EXAONE, Solar Mini 외에도 국내 스타트업과 대기업들의 한국어 특화 SLM 개발이 가속화되고 있습니다. 2026년에는 법률·의료·금융 등 전문 도메인에 특화된 한국어 SLM들이 본격 상용화될 전망입니다.
④ SLM 파인튜닝 플랫폼 생태계 성숙: 코딩 없이 자체 데이터로 SLM을 파인튜닝할 수 있는 AutoML형 플랫폼들이 등장하면서, AI 전문가 없이도 도메인 특화 SLM을 구축하는 것이 현실화되고 있습니다.
⑤ 규제 대응형 SLM 수요 증가: EU AI Act, 국내 AI 기본법 등 AI 규제가 강화되면서 데이터를 외부로 보내지 않는 온프레미스·온디바이스 SLM에 대한 수요가 금융·의료·공공 분야에서 급증할 전망입니다.
---
❓ 자주 묻는 질문 (FAQ)
Q1. SLM과 LLM, 실제 성능 차이가 체감될 정도인가요?
작업 유형에 따라 다릅니다. 문서 분류, 감성 분석, 단순 요약처럼 패턴이 정해진 작업에서는 잘 튜닝된 SLM이 GPT-4와 성능 차이를 거의 느끼기 어렵습니다. 반면 복잡한 다단계 추론, 전문 지식 기반 창의적 작문에서는 차이가 명확합니다. 도입 전 PoC로 실제 업무 데이터를 테스트하는 것이 가장 정확한 판단 방법입니다.
Q2. SLM 파인튜닝에 얼마나 많은 데이터가 필요한가요?
놀랍게도 생각보다 적은 데이터로도 효과적인 파인튜닝이 가능합니다. LoRA/QLoRA 기법을 활용하면 500~2,000건의 고품질 레이블 데이터로도 도메인 특화 성능을 크게 높일 수 있습니다. 다만 데이터 품질이 양보다 훨씬 중요합니다.
Q3. 온디바이스 AI로 사용자 데이터 보안이 정말 보장되나요?
온디바이스 AI는 모든 처리가 사용자의 기기 내에서 완결되므로, 데이터가 외부 서버로 전송되지 않습니다. GDPR·개인정보보호법 관점에서 가장 안전한 아키텍처입니다. 다만 기기 내 모델 파일 자체의 보안(역공학 방지)은 별도 기술적 조치가 필요합니다.
Q4. GPU 서버 없이 SLM을 운영할 수 있나요?
가능합니다. llama.cpp, Ollama 같은 도구를 활용하면 일반 CPU 서버나 Mac에서도 SLM 추론이 가능합니다. 물론 GPU 대비 속도는 느리지만, 트래픽이 많지 않은 내부 업무 자동화나 프로토타입 단계에서는 충분히 활용 가능합니다. 소규모 팀이라면 M2 Mac 미니 한 대로도 2~4B SLM 서비스를 운영할 수 있습니다.
Q5. 여러 SLM을 동시에 운영하는 것이 유리한가요?
고급 AI 서비스 아키텍처에서는 "SLM 앙상블" 또는 "라우팅 기반 멀티모델" 구조가 점점 표준화되고 있습니다. 예를 들어 한국어 분류는 EXAONE, 영어 코드 생성은 Phi-4, 온디바이스 기능은 Llama 3.2-1B로 라우팅하는 구조입니다. 비용과 성능의 최적점을 찾으려면 이런 멀티모델 전략을 검토해 볼 만합니다.
---
🚀 마무리: SLM은 '차선책'이 아니라 '전략적 선택'입니다
지금까지 살펴본 것처럼, 소형 언어모델(SLM)은 대형 LLM의 열등한 대안이 아닙니다. 올바른 작업에 올바른 모델을 배치하면 GPT-4 비용의 1/100로도 동등하거나 더 나은 비즈니스 결과를 얻을 수 있습니다. Phi-4의 코딩 능력, EXAONE의 한국어 특화 성능, Llama 3.2의 온디바이스 최적화, Qwen 2.5의 다국어 지원은 각각의 영역에서 대형 모델이 갖지 못한 특화된 강점을 제공합니다.
2026년을 앞두고 AI 도입은 더 이상 선택이 아닌 생존의 문제가 되고 있습니다. SLM은 그 진입 장벽을 획기적으로 낮춰주는 기술입니다. 지금 당장 모든 것을 완벽하게 구축하지 않아도 됩니다. 작은 PoC부터 시작해 데이터를 쌓고, 점진적으로 확장하는 것이 가장 현명한 SLM 도입 전략입니다.
SLM 도입 전략 수립, 모델 선정, 파인튜닝, 인프라 설계까지 전 과정의 기술 자문이 필요하시다면 아래 서명 블록을 참고해 주세요. 귀사의 서비스에 최적화된 SLM 아키텍처를 함께 설계해 드립니다. 🎯
🏢 VIZENSOFT | AI 솔루션 컨설팅 & SLM 도입 전략 전문
📧 | 🌐 | 📞
AI 도입의 첫 걸음, 올바른 모델 선택에서 시작됩니다. 지금 비젠소프트와 함께 귀사만의 최적 SLM 아키텍처를 설계해 보세요! 🚀
🔗






